文章汇总:
近年来容器化越来越火,docker,k8s成为应用部署的主流方式。当我们复现漏洞的时候,都习惯于使用docker,快速方便,统一环境,何况需要分布式,高可用的服务。
所以当你拿到了shell,进行后渗透的时候,也许还在别人的容器中遨游,为了突破这种困境,所以尝试总结一下docker的安全性问题,包括docker的原理和逃逸手段,后续也许会更新k8s的安全问题。
1. docker和虚拟机的区别
先看一张图:
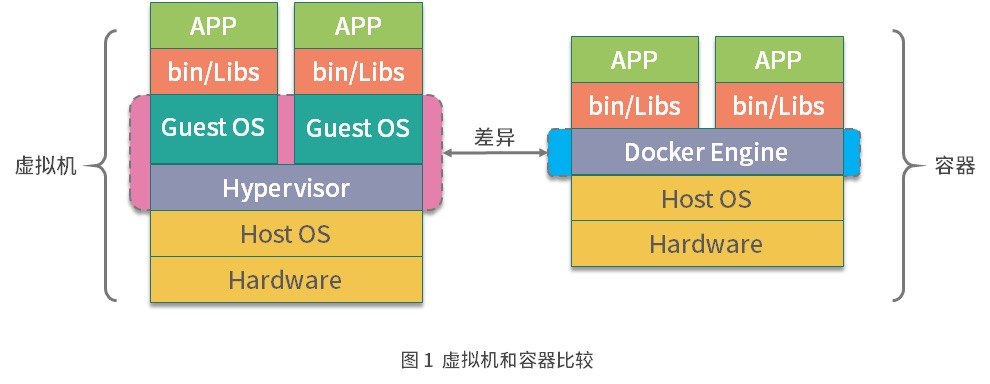
虚拟机利用Hypervisor,在主操作系统之上创建虚拟层,虚拟化的操作系统,然后再安装应用。
docker在主操作系统之上创建Docker引擎,在引擎的基础上再安装应用,所以docker还是利用了宿主机的操作系统,也就是使用主机的内核。
所以docker container可以看作是主机上运行的一个进程而已,而虚拟机和主机则是完全隔离的。

2. 通过Namespace实现隔离
Namespace 是 Linux 内核的一个特性,该特性可以实现在同一主机系统中,对进程ID、主机名、用户 ID、文件名、网络和进程间通信等资源的隔离。Docker 利用 Linux 内核的 Namespace 特性,实现了每个容器的资源相互隔离,从而保证容器内部只能访问到自己 Namespace 的资源。
docker使用了以下的Namespace
| Namespace名称 | 作用 |
|---|---|
| Mount(mnt) | 隔离挂载点 |
| Process ID (pid) | 隔离进程 ID |
| Network (net) | 隔离网络设备,端口号等 |
| Interprocess Communication (ipc) | 隔离 System V IPC 和 POSIX message queues |
| UTS Namespace(uts) | 隔离主机名和域名 |
| User Namespace (user) | 隔离用户和用户组 |
下面实践一下PID Namespace的使用来理解什么是namespace。
首先我们创建一个 bash进程,并且新建一个PID Namespace:
$ sudo unshare --pid --fork --mount-proc /bin/bash
root@yanq:/home/yanq#
在新的bash进程使用 ps aux 命令查看一下进程信息:
root@yanq:/home/yanq# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 12920 3880 pts/4 S 00:41 0:00 /bin/bash
root 8 0.0 0.0 14584 3240 pts/4 R+ 00:42 0:00 ps aux
可以看到当前Namespace下bash为1号进程,而且看不到宿主机上的其他进程。
当创建container时,Docker会创建这六种Namespace,然后将container中的进程加入这些Namespace之中,使得Docker 容器中的进程只能看到当前Namespace中的系统资源,实现了Docker容器的隔离。
当使用docker run –net=host命令启动容器时,容器和主机共享同一个Net Namespace,所以才会直接使用主机上的网卡和ip。
3. 通过Cgroups机制实现资源限制
使用不同的Namespace可以实现隔离,但是容器内的进程仍然可以任意地使用主机的CPU 、内存等资源,Docker是通过Cgroups机制实现对容器的资源限制的。
cgroups(control groups)是Linux内核的一个功能,它可以实现限制进程或者进程组的资源(如CPU、内存、磁盘IO等)。依赖于三个核心概念:子系统、控制组、层级树。其中子系统是最核心的组件,一个子系统代表一类资源调度控制器。例如内存子系统可以限制内存的使用量,CPU 子系统可以限制 CPU 的使用时间。
查看系统有哪些子系统
# yanq @ yanq in ~ [1:02:17]
$ sudo sudo mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
可以看到系统已经挂载了常用的cgroups子系统,例如cpu、memory、pids等。下面以cpu 子系统为例,演示一下cgroups如何限制进程的cpu使用时间:
# 1. 在cpu子系统下创建cgroup,只需要在相应的子系统下创建目录即可
root@yanq:~# mkdir /sys/fs/cgroup/cpu/test
root@yanq:~# ls -l /sys/fs/cgroup/cpu/test
总用量 0
-rw-r--r-- 1 root root 0 1月 29 01:06 cgroup.clone_children
-rw-r--r-- 1 root root 0 1月 29 01:06 cgroup.procs
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.stat
-rw-r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage_all
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage_percpu
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage_percpu_sys
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage_percpu_user
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage_sys
-r--r--r-- 1 root root 0 1月 29 01:06 cpuacct.usage_user
-rw-r--r-- 1 root root 0 1月 29 01:06 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 1月 29 01:06 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 1月 29 01:06 cpu.shares
-r--r--r-- 1 root root 0 1月 29 01:06 cpu.stat
-rw-r--r-- 1 root root 0 1月 29 01:06 cpu.uclamp.max
-rw-r--r-- 1 root root 0 1月 29 01:06 cpu.uclamp.min
-rw-r--r-- 1 root root 0 1月 29 01:06 notify_on_release
-rw-r--r-- 1 root root 0 1月 29 01:06 tasks
# 2. 修改这个cgroup的cpu限制时间为0.5核
# 其中cpu.cfs_quota_us代表在某一个阶段限制的CPU时间总量,单位为微秒。
# 例如,我们想限制该cgroup最多使用0.5核CPU,就在这个文件里写入50000(100000代表限制1个核)
root@yanq:~# cd /sys/fs/cgroup/cpu/test
root@yanq:/sys/fs/cgroup/cpu/test# echo 50000 > cpu.cfs_quota_us
# 3. 将当前进程加入此cgroup
root@yanq:/sys/fs/cgroup/cpu/test# echo $$ > tasks
root@yanq:/sys/fs/cgroup/cpu/test# cat tasks
4016539
4016709
# 4. 验证cgroup是否可以限制cpu使用时间
root@yanq:/sys/fs/cgroup/cpu/test# while true;do echo;done;
然后打开一个新窗口,查看4016539进程的cpu使用率
$ top -p 4016539
top - 01:15:49 up 6 days, 43 min, 1 user, load average: 1.89, 1.44, 1.19
任务: 1 total, 1 running, 0 sleeping, 0 stopped, 0 zombie
%Cpu(s): 15.0 us, 15.4 sy, 0.1 ni, 69.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 14942.0 total, 1685.6 free, 7290.4 used, 5966.0 buff/cache
MiB Swap: 2048.0 total, 1555.0 free, 493.0 used. 6814.2 avail Mem
进程号 USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
4016539 root 20 0 12920 3952 3340 R 50.3 0.0 0:44.06 bash
# 5. 最后删除测试的cgroup
root@yanq:~# rmdir /sys/fs/cgroup/cpu/test
Docker创建容器时,会根据启动容器的参数,在对应的cgroups子系统下创建以容器ID为名称的目录, 然后根据容器启动时设置的资源限制参数, 修改对应的cgroups子系统资源限制文件, 从而达到资源限制的效果。
4. docker 网络实现原理
Docker从1.7版本开始,便把网络和存储从Docker 中正式以插件的形式剥离开来,并且分别为其定义了标准,Docker定义的网络模型标准称之为 CNM (Container Network Model) 。CNM 只是定义了网络标准,对于底层的具体实现并不太关心,这样便解耦了容器和网络,使得容器的网络模型更加灵活。
其中Libnetwork是CNM的官方实现,是Docker启动容器时,用来为Docker 容器提供网络接入功能的插件。Libnetwork 比较典型的网络模式主要有四种:
- null 空网络模式:可以帮助我们构建一个没有网络接入的容器环境,以保障数据安全。
- bridge 桥接模式:可以打通容器与容器间网络通信的需求。
- host 主机网络模式:可以让容器内的进程共享主机网络,从而监听或修改主机网络。
- container 网络模式:可以将两个容器放在同一个网络命名空间内,让两个业务通过 localhost 即可实现访问。
4.1 null空网络模式
使用null模式时,Docker只是为容器创建了一个Net Namespace,没有进行网卡接口、IP 地址、路由等网络配置。
# 启动一个没有null模式的容器
$ docker run --net=none -it busybox
# 没有创建任何虚拟网卡
/ # ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
# 没有配置任何路由信息
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
4.2 bridge 桥接模式
桥接网络为默认选项,容器使用独立的net namespace并且连接到docker0虚拟网卡(当Docker server启动时,就创建一个名为docker0的虚拟网桥)。并且配置Iptables nat表,使得容器可以与宿主机通信。其配置过程如下:
- 在主机上创建一对虚拟网卡veth pair设备。
veth 是 Linux 中的虚拟设备接口,veth 都是成对出现的,它在容器中,通常充当一个桥梁。veth 可以用来连接虚拟网络设备,例如 veth 可以用来连通两个 Net Namespace,从而使得两个 Net Namespace 之间可以互相访问。
- Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0。另一端放在主机中,以veth65f9这样类似的名字命名,并将这个网络设备加入到docker0网桥中,可以通过brctl show命令查看。
# yanq @ yanq in ~ [11:07:24] C:127
$ brctl show
bridge name bridge id STP enabled interfaces
br-29042ff28131 8000.02421877c92b no
docker0 8000.02429c930098 no
virbr0 8000.525400c3aac4 yes virbr0-nic
- 从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。
# yanq @ yanq in ~ [11:09:59]
$ docker run -d --name=bridge_test --net=bridge -it busybox
d9a543d5ae18acf1c666159b206553cd80ed34e3f5be096b60fdd29f2419e239
# yanq @ yanq in ~ [11:10:17]
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d9a543d5ae18 busybox "sh" 3 seconds ago Up 2 seconds bridge_test
# 查看容器网络
# yanq @ yanq in ~ [11:10:20]
$ docker inspect d9a543d5ae18
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "a0712bf93f3e6ca23471e5d62caf4430b44627b6988ab24cf5a8ed61d9db207a",
"EndpointID": "ad5524fca3ea9272876385e3a306c8ec0883c60d7888bc495b0e01f23e96ae27",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null
}
}
# 查看网桥信息,会看到有有一个容器
# yanq @ yanq in ~ [11:11:10] C:1
$ docker network inspect bridge
[
{
"Name": "bridge",
"Id": "a0712bf93f3e6ca23471e5d62caf4430b44627b6988ab24cf5a8ed61d9db207a",
"Created": "2021-01-23T17:19:37.51657082+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"d9a543d5ae18acf1c666159b206553cd80ed34e3f5be096b60fdd29f2419e239": {
"Name": "bridge_test",
"EndpointID": "ad5524fca3ea9272876385e3a306c8ec0883c60d7888bc495b0e01f23e96ae27",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
容器和容器之可以互相通信,容器和外部网络之间也可以相互通信,看一下主机上的Iptable规则会发现有这一条:
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
这条规则会将源地址为172.17.0.0/16的包,并且不是从docker0网卡发出的,进行源地址转换,转换成主机网卡的地址。此时容器中ping百度,包会到到docker0网关,也就是到达了主机上,主机查看路由表,发现包应该从主机的eth0发往主机的网关,于是包达到了主机的eth0,此时这条规则会对包进行SNAT转换,将源地址换为eth0的地址,从外界看起来也就是主机去访问百度。
4.3 host 主机网络模式
使用host主机网络模式时:
- libnetwork不会为容器创建新的网络配置和Net Namespace。
- Docker容器中的进程直接共享主机的网络配置,可以直接使用主机的网络信息,此时,在容器内监听的端口,也将直接占用到主机的端口。
host 主机网络模式通常适用于想要使用主机网络,但又不想把运行环境直接安装到主机上的场景中
4.4 container 网络模式
container 网络模式允许一个容器共享另一个容器的网络命名空间。当两个容器需要共享网络,但其他资源仍然需要隔离时就可以使用container网络模式,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。
5. 联合文件系统
Docker主要是基于Namespace、cgroups 和联合文件系统这三大核心技术实现。联合文件系统(Union File System,Unionfs)是一种分层的轻量级文件系统,它可以把多个目录内容联合挂载到同一目录下,从而形成一个单一的文件系统,这种特性可以让使用者像是使用一个目录一样使用联合文件系统。
利用联合文件系统,Docker可以把镜像做成分层的结构,从而使得镜像的每一层可以被共享。例如两个业务镜像都是基于 CentOS 7 镜像构建的,那么这两个业务镜像在物理机上只需要存储一次 CentOS 7 这个基础镜像即可,从而节省大量存储空间。
联合文件系统只是一个概念,真正实现联合文件系统才是关键,Docker中最常用的联合文件系统有三种:AUFS、Devicemapper 和 OverlayFS。
6. docker volume
6.1 volume的使用
有时候需要用到docker的存储功能,比如mysql的持久化,这时候我们可以将container的数据挂载到主机上,这就是利用了docker的volume功能。
使用docker volume命令可以实现对卷的创建、查看和删除等操作
- 创建
docker volume create myvolume
- 查看卷
docker volume ls
docker volume inspect myvolume
$ docker volume inspect myvolume
[
{
"CreatedAt": "2021-01-30T15:59:40+08:00",
"Driver": "local",
"Labels": {},
"Mountpoint": "/opt/docker/volumes/myvolume/_data",
"Name": "myvolume",
"Options": {},
"Scope": "local"
}
]
- 使用
# 使用上一步创建的卷来启动一个 nginx 容器,并将 /usr/share/nginx/html 目录与卷关联,命令如下:
docker run -d --name=nginx --mount source=myvolume,target=/usr/share/nginx/html nginx
- 删除
docker volume rm myvolume
怎么实现两个docker的数据共享。(比如两个docker容器共享一个日志目录)?
首先创建一个卷
docker volume create log-vol
然后创建两个容器公用这个卷就行了
docker run --mount source=log-vol,target=/tmp/log --name=log-producer -it busybox
docker run -it --name consumer --volumes-from log-producer busybox
(使用volumes-from参数可以在启动新的容器时来挂载已经存在的容器的卷,volumes-from参数后面跟已经启动的容器名称。)
6.2 docker volume的原理
镜像和容器的文件系统原理: 镜像是由多层文件系统组成的,当我们想要启动一个容器时,Docker 会在镜像上层创建一个可读写层,容器中的文件都工作在这个读写层中,当容器删除时,与容器相关的工作文件将全部丢失。
所以Docker容器的文件系统不是一个真正的文件系统,而是通过联合文件系统实现的一个伪文件系统,而 Docker卷则是直接利用主机的某个文件或者目录,它可以绕过联合文件系统,直接挂载主机上的文件或目录到容器中,这就是它的工作原理。
Docker卷的实现原理是在主机的/var/lib/docker/volumes目录下,根据卷的名称创建相应的目录,然后在每个卷的目录下创建 _data 目录,在容器启动时如果使用 –mount 参数,Docker会把主机上的目录直接映射到容器的指定目录下,实现数据持久化。
$ sudo ls /var/lib/docker/volumes
0fa44b5d0b895302ec28e5c8c94568d1b14af8415860c5be8910bd0c4f2839de
9e5e71d7a87257b317bc05f1b2174d1a3ed7dd23b9d7832b8685dcd95ceaac91
可以理解为docker -v就是创建或者使用一个volume。 -v 参数可以挂载主机任意目录,卷是Docker 对目录的封装,只需要指定卷的名称即可使用
7. docker组件
Docker整体架构采用C/S模式,主要由客户端和服务端两大部分组成。客户端负责发送操作指令,服务端负责接收和处理指令。客户端和服务端通信有多种方式,即可以在同一台机器上通过UNIX套接字通信,也可以通过网络连接远程通信。

docker的组件有:
- docker docker客户端
- dockerd: docker服务端
Docker 客户端与 dockerd 的交互方式有三种。
通过 UNIX 套接字与服务端通信:配置格式为unix://socket_path,默认 dockerd 生成的 socket 文件路径为 /var/run/docker.sock,该文件只有 root 用户或者 docker 用户组的用户才可以访问,这就是为什么 Docker 刚安装完成后只有 root 用户才能使用 docker 命令的原因。
通过 TCP 与服务端通信:配置格式为tcp://host:port,通过这种方式可以实现客户端远程连接服务端,但是在方便的同时也带有安全隐患,因此在生产环境中如果你要使用 TCP 的方式与 Docker 服务端通信,推荐使用 TLS 认证,可以通过设置 Docker 的 TLS 相关参数,来保证数据传输的安全。
通过文件描述符的方式与服务端通信:配置格式为:fd://这种格式一般用于 systemd 管理的系统中。
docker-init: 在容器内部,当我们自己的业务进程没有回收子进程的能力时,在执行docker run启动容器时可以添加 –init 参数,此时Docker会使用docker-init作为1号进程,帮你管理容器内子进程,例如回收僵尸进程等
docker-proxy: 用来做端口映射,当我们启动容器使用了-p参数,docker-proxy组件就会把容器内相应的端口映射到主机上来,底层是依赖于iptables实现的
containerd:containerd 组件是从Docker 1.11正式从dockerd中剥离出来的,containerd不仅负责容器生命周期的管理,同时还负责一些其他的功能:
- 镜像的管理,例如容器运行前从镜像仓库拉取镜像到本地
- 接收 dockerd 的请求,通过适当的参数调用runc启动容器
- 管理存储相关资源
- 管理网络相关资源
containerd包含一个后台常驻进程,dockerd通过UNIX套接字向containerd发送请求,containerd接收到请求后负责执行相关的动作并把执行结果返回给dockerd。
- containerd-shim:将 containerd 和真正的容器进程解耦,使用containerd-shim作为容器进程的父进程,从而实现重启containerd不影响已经启动的容器进程。
- ctr:ctr可以充当docker客户端的部分角色,直接向containerd守护进程发送操作容器的请求。用于调试和开发。
- runc:runc 是一个标准的 OCI 容器运行时的实现,它是一个命令行工具,通过调用Namespace、Cgroup等系统接口,负责真正意义上创建和启动容器。
其中比较重要的组件就是docker、dockerd、runc。