基于LSTM深度模型实现系统日志异常检测
文章最后更新时间为:2020年06月02日 01:05:51
1. 背景
主机系统运行过程中会产生各种各样的日志,日志记录了计算机运行时的状态和系统执行的各种操作,是在线监视和异常检测的良好信息来源,因此对系统日志的审计可以作为主机异常检测的重要手段。
市场早已经存在各种各样的安全审计系统,比如日志审计系统、入侵检测系统(intrusion detection system,IDS)等,这些系统可以实现日志的采集、审计和异常行为挖掘的功能。但是在实际使用中,由于日志的差异和日志审计手段的单一落后,这些系统往往只适用于特定类型的主机,且能检测到的异常行为不够全面和准确。
近年来,随着机器学习的发展,数据挖掘能力进一步提升,基于机器学习进日志审计的研究成果不断出现。但是对于不同的主机系统和进程,其产生的日志类型是不一致的,传统机器学习检测方法需要对不同类型的日志使用不同的特征提取方法,需要使用者有专业的知识背景才能更好的抽取日志的特征信息。在现实情况中日志的种类和语法是在不断更新的,某一种方法无法直接应用于多个系统,需要花费大量人力成本来做更新和匹配。
相对比较高级的就是使用深度学习来做异常检测。系统日志的数据量越来越大已经足够深度学习模型进行学习处理,在参数合适的情况下,几乎不需要人工提取特征,深度学习模型就能很好的完成日志检测。下面主要讨论如何利用LSTM模型来实现日志的异常检测。
2. 实现原理
2017年李飞飞和她的团队发表论文:Deeplog: Anomaly detection and diagnosis from system logs through deep learning,提出了基于SLTM的日志异常检测模型,重点提出了工作流模型。这里我们暂时不探讨工作流模型,只是初步提出其异常检测的原理并给出实现。
每一行日志都是源代码的输出语句生成的。比如某个进程的源代码中的日志打
印语句为printf("Accepted password for %s from %s port %d ssh2 \n", user, host, port),那么在程序的运行过程中,就可能会产生Feb 28 04:48:54 combo sshd(pam_unix)[6741]: Accepted password for root from 112.64.243.186 port 2371 ssh2。一条源代码打印出的日志为同一类型,其代码称为日志键。
系统产生的日志是有一定的逻辑性的,比如下面几条日志:
1 Jun 26 04:10:02 combo su(pam_unix)[1546] session opened for user news by (uid=0)
2 Jun 26 04:10:04 combo su(pam_unix)[1546] session closed for user news
3 Jun 27 04:02:47 combo su(pam_unix)[7031] session opened for user cyrus by (uid=0)
4 Jun 27 04:02:48 combo su(pam_unix)[7031] session closed for user cyrus相邻或者相近日志的关联度很高,一条日志往往取决于前一条或者前几条日志,当这种逻辑性被某条日志打破,则说明发生了日志执行路径异常。
因此我们可以将日志执行顺序看作成一个多分类问题,日志键的总数是一定的,我们看作为K,在训练阶段我们输入正常的日志执行序列,生成一个多分类器模型。在测试阶段,我们输入最近日志键的历史记录,输出是一个日志键的概率分布。如下图所示:
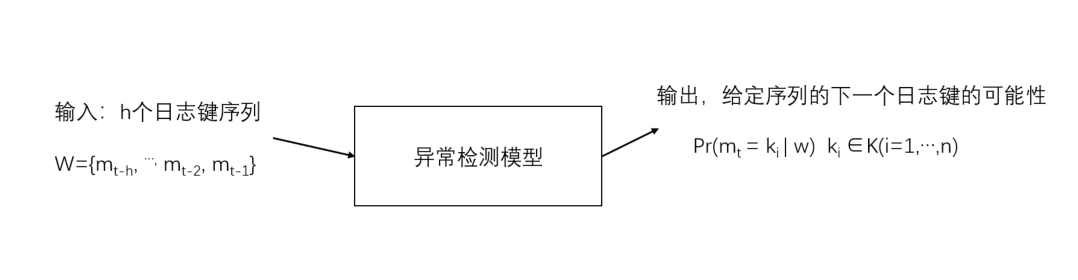
当序列预测的结果和实际结果误差较大时,我们则可以认为该日志属于异常。
日志可以分为日志键和日志参数,日志参数也可能会出现异常情况,比如温度监控太高、CPU占用过多等。在Deeplog中也是用序列预测的方式去做,但是我个人觉得不太具有理论上的意义。
总结来说实现日志检测的原理其实就是利用深度学习进行序列预测。
3. 具体实现
3.1 日志解析
日志可以分为日志键和日志参数,我们首先要将两者分离开,将日志解析成结构化。实现的目标如下:

Shilin He等人实现了多种日志解析的方法,并在github上提供了开源的源代码:https://github.com/logpai/logparser。
在这里我们选用了Spell方式,详细信息可以戳这里。解析日志的完整过程如下:
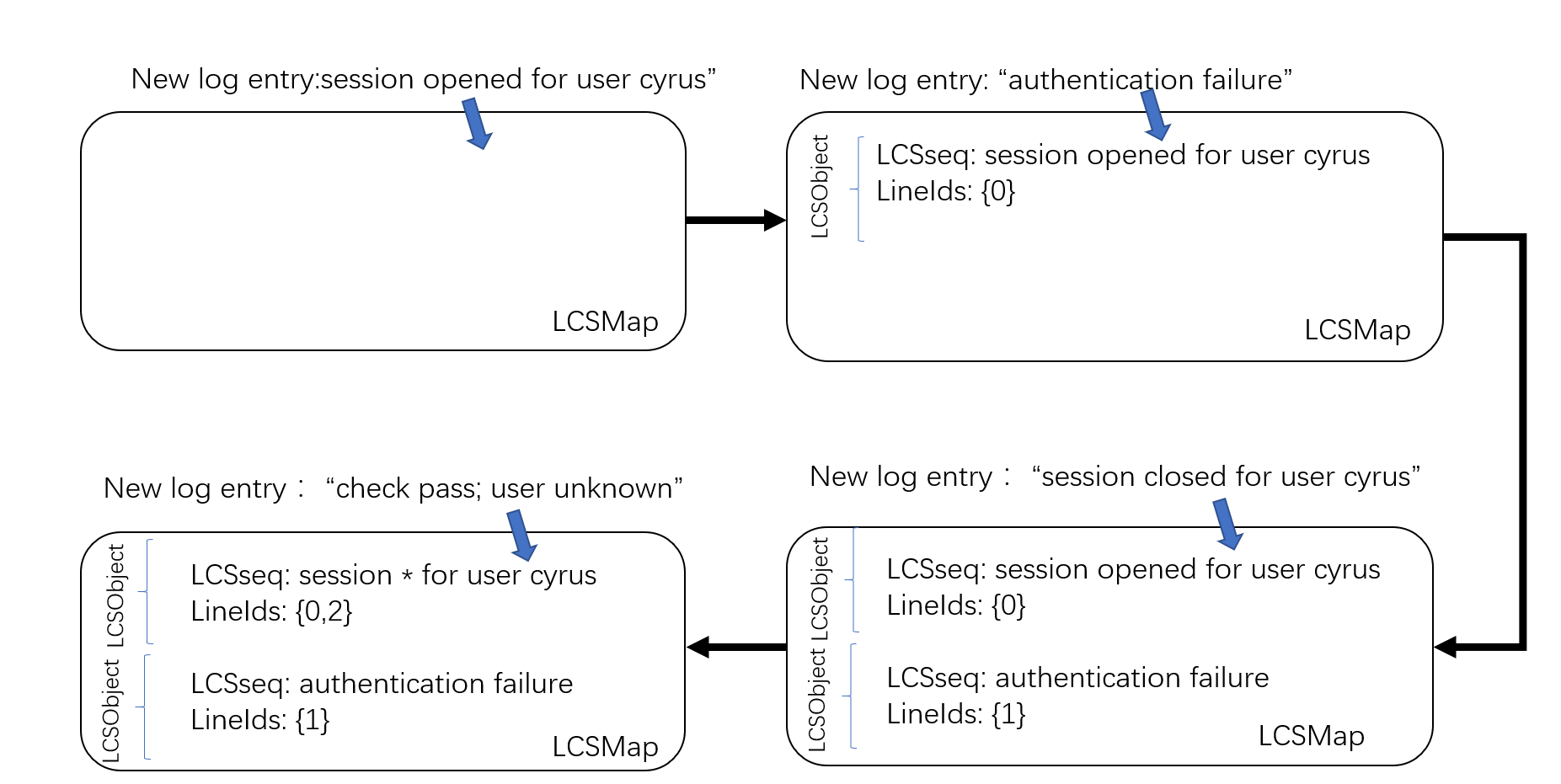
- 初始化,包括(1)日志对象LCSObject,包括日志模板LCSseq和行数列表lineIds;(2)存放所有日志对象的列表LCSMap。
- 流式的读取日志
- 当读取到一个新的日志条目之后,遍历LCSMap,寻找该日志与所有LCSObject的最大公共子序列,如果子序列的长度大于日志序列长度的一半,则认为该日志该与日志键匹配。如果找到匹配的日志对象,跳转5,如果没有,或者LCSMap为空,则跳转第4步;
- 将该行日志初始化为一个新的LCSObject,放入列表LCSMap中。
- 将该行日志更新到匹配的LCSObject的行数列表lineIds中,并且更新LCSseq。
- 跳转到第2步,直到日志读取完毕。
3.2 特征提取
在日志解析完成后,我们已经得到系统的结构化日志,但是此时日志键还只是字符串的形式,参数列表元素也还是字符串,无法直接作为深度学习模型的输入,所以我们还需要将其特征化为数字形式的特征向量。特征提取的过程就是将字符串中转换为可量化的数字,从而构造矩阵作为特征向量,对于日志键和参数,由于其形成的方式和表达的意义不同,我们采用了两种不同的特征化方法。
- 日志键编码
由于日志是由程序或者进程的代码输出,其代码是恒定的,所以输出日志的种类也是恒定的,而且数量往往不是很大。所以对于日志键,直接采用顺序数字编号的方式来进行编码。比如日志键K1,K2,K3,我们直接将其特征化为1,2,3
- 日志参数编码
和日志类型不同的是,参数值不是由模板生成的,而是在系统运行过程中根据实际发生的情况动态产生的,所以其往往具有很大的不确定性,参数值的字符串类型将会很多,直接使用简单的整数排列编码将会导致线性长度过大。
我的做法是首先提取出所有的参数列表,进行参数预处理,去除所有的标点符号和特殊字符,因为这些字符是不作为参数异常的评判标准的,所以可能会影响字符的准确性。然后将所有的参数字符串去重组成一个token列表,利用深度学习库keras下的text.Tokenizer模块对字符串进行处理,使用fit_on_texts方法学习出文本的字典,就是对应的单词和数字的映射关系,统计参数值的词频等信息。然后使用text.Tokenizer模块的texts_to_sequences函数将参数文本转化为数字,将不同长度的序列使用0补齐为同样长度。
3.3 异常检测
给定小部分正常的日志键序列,然后输入LSTM模型进行训练。得到一个检测模型,在系统正常运行时,收集到系统产生的日志序列,经过日志解析和特征提取之后得到一个日志键序列,然后用LSTM模型去预测该序列后一条日志键的可能性,如果实际情况中的下一条日志在可能性分布中具有较大的概率,那么认为这条日志属于正常日志,否则判定为异常。
在训练阶段模型需要找到适当的权重分配,以使LSTM序列的最终输出产生所需的标签,并随训练数据集中的输入一起输出。在训练过程中,每个输入和输出利用梯度下降法找到最小损失来更新这些参数权重,输入为日志序列,输出是紧随此日志序列之后的日志键值。在训练中,日志健使用的损失函数是分类父叉熵损失(categorical cross-entropy loss),参数使用均方损失(mean square loss)来进行误差的度量
在检测阶段我们使用一个含有h个LSTM块的层对一个输入序列w进行输出预测,将w的每个日志键都加入该层所对应的LSTM块。我们使用了多个隐藏层,并使用上一层的隐藏状态作为下一层中每个相应的LSTM块的输入,将模型变成一个深层的LSTM神经网络,输入层将来自所有日志键类型K中的n个日志编码为one-hot向量。输出层利用一个标准多项式逻辑函数(standart mulnomial logistic function)将输出转换为一个概率分布函数。当模型预测日志键和实际日志键出现较大差异时,超过了我们定义的阈值,则认定该日志发生了执行路径异常。
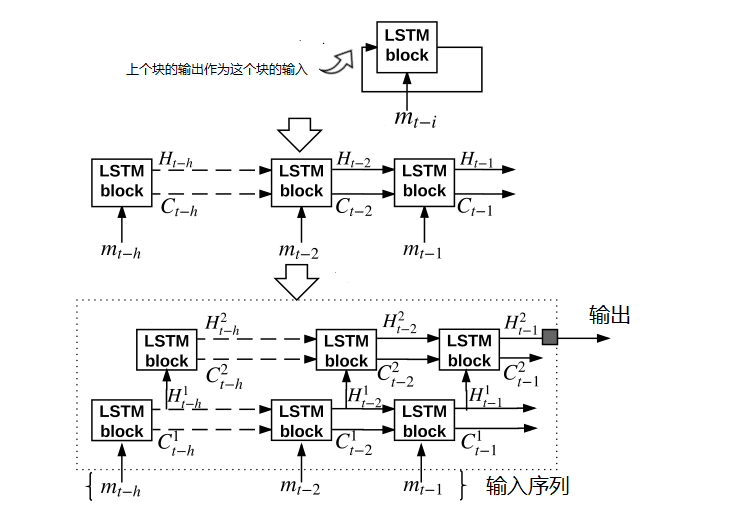
基于LSTM进行异常检测的模型架构如上图所示,图的顶部显示了一个LSTM模块,重复的LSTM块组成了整个架构。每一个LSTM模块都会记录一个状态,作为一个固定维度的向量。来自上一个时间步的LSTM模块的状态和其外部输入mt-i会一起作为下一个LSTM模块的输入,用来计算新的状态和输出,这种方式保证了日志序列中日志信息能够传递到下一个LSTM块中。
一系列LSTM块在一层中形成了循环模式的展开形式,如上图的中部所示。每个单元都保留一个隐藏向量Ht-i和一个单元状态向量Ct-i,两者都传递到下一个块以初始化其状态。在我们的系统中,对于输入序列w中的每个日志键,我们使用一个LSTM块。因此,一个单层由h个展开的LSTM块组成,在一个单独的LSTM块中,输入mt-i和前一个块的输出Ht-i-1可以决定:
(1)在状态Ct-i中保留前一个单元状态Ct-i-1的程度
(2)怎么使用当前输入和之前的输出去影响状态
(3)如何构建输出Ht-i
LSTM是使用一组门函数来确定的,这些函数通过控制前一个LSTM块保留的状态和前一个块中的输出信息以及当前块的输入信息流来确定状态。每个门函数通过一组要学习的权重进行参数化。
LSTM模型实际上也有升级和改进的措施,比如GRU模型,或者嵌入层、Dropout层的使用,还是得就具体情况而定,这里就不多做介绍了。关于异常检测这一块,深度模型其他的更多是调参了~
4. 实验与评估
该部分只评估了日志键异常检测的部分,编程环境为Python3.7.3,基于keras2、tensorflow2(cpu)。
数据使用了公开的HDFS日志数据集。HDFS数据包含11175629条日志消息,是从亚马逊EC2平台收集的Hadoop日志,并且被相关领域专家标记为正常或者异常。下载地址:https://zenodo.org/record/3227177/files/HDFS_1.tar.gz?download=1
默认使用以下的参数值g=10,h=10,num_layers=2和hidden_size=64来训练深度学习模型。其中g为代表预测输出中属于正常情况的范围(概率为前g个则视为正常日志),h为序列窗口大小,num_layers和hidden_size分别代表了LSTM模型中的隐藏层数和隐藏层大小。
采用控制变量法进行参数调整,结果如下
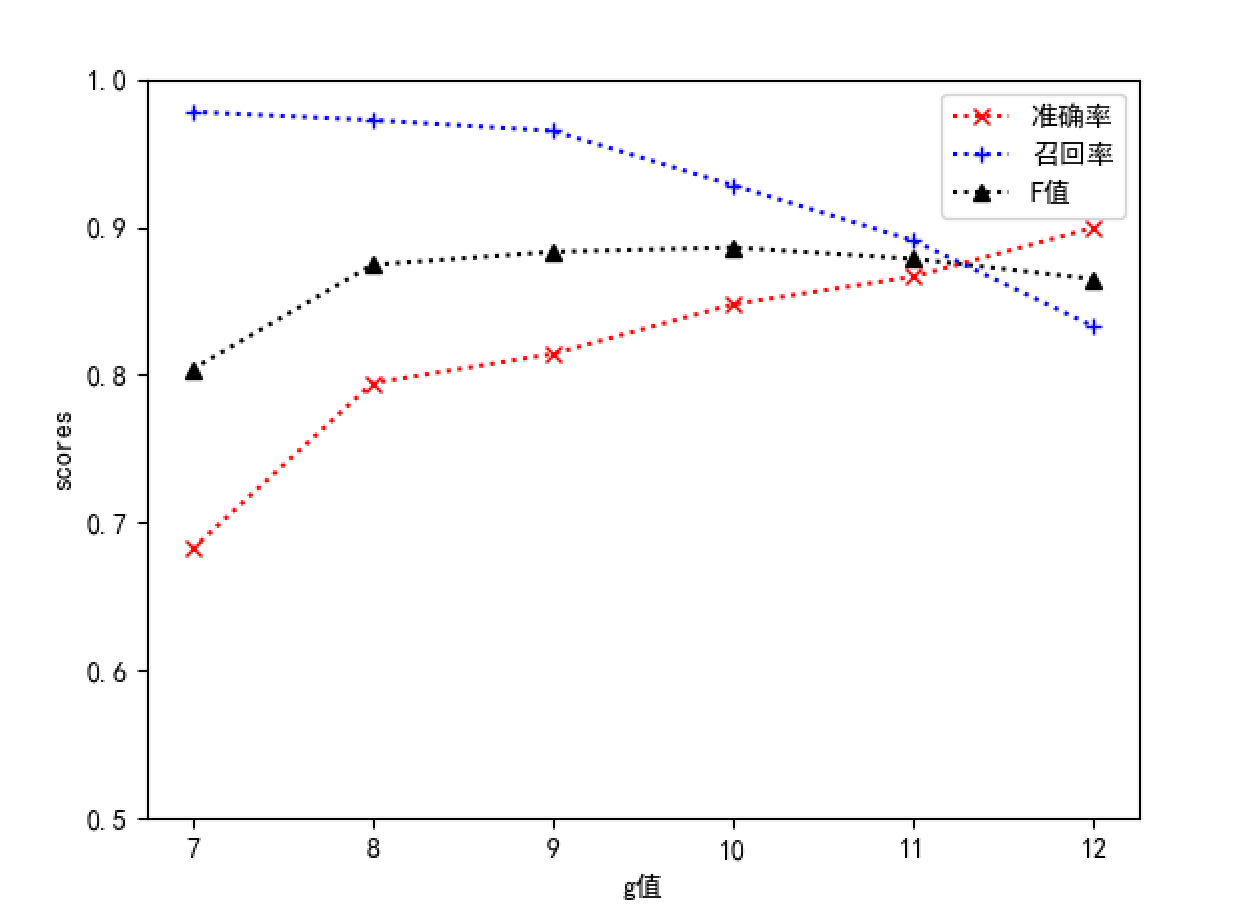
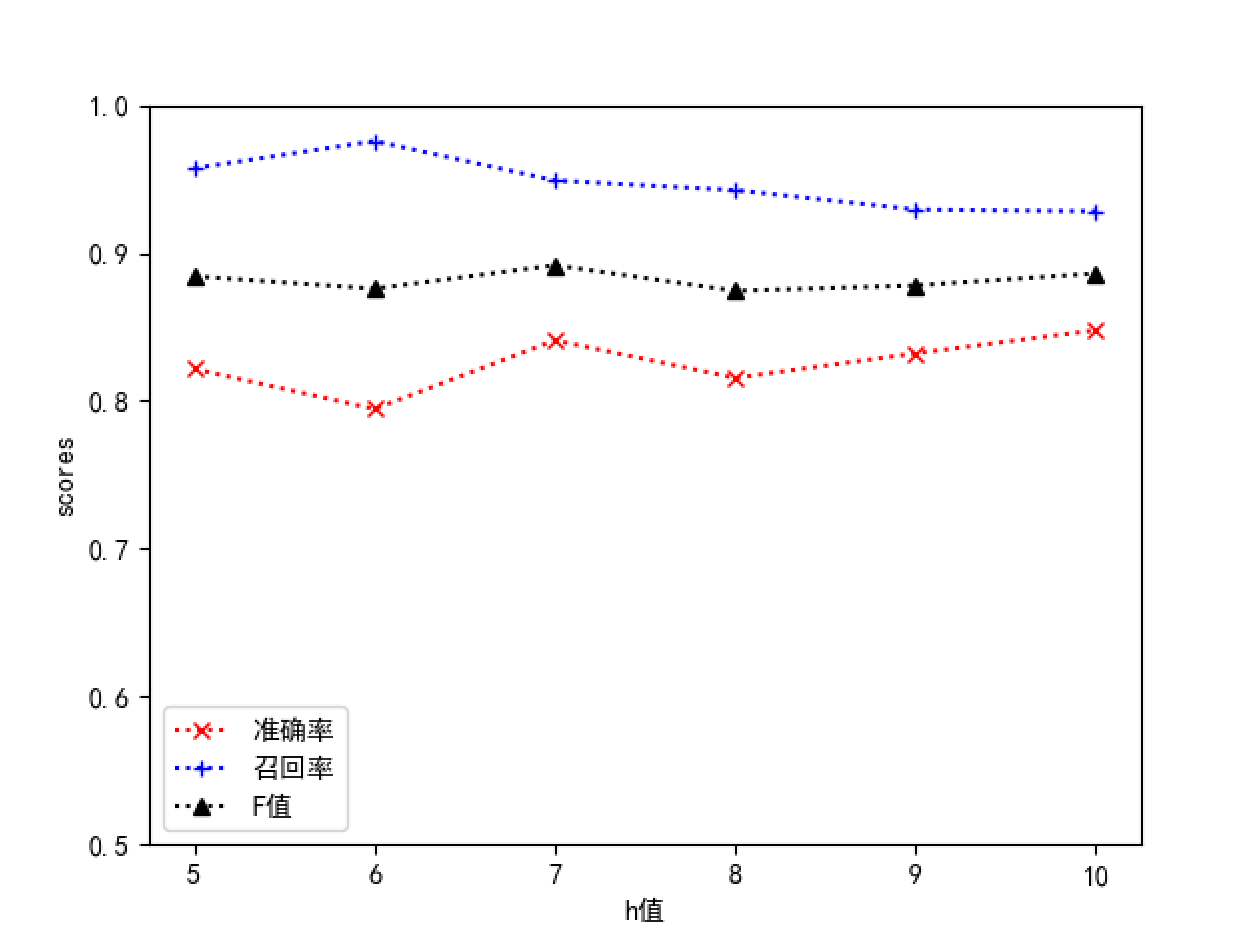

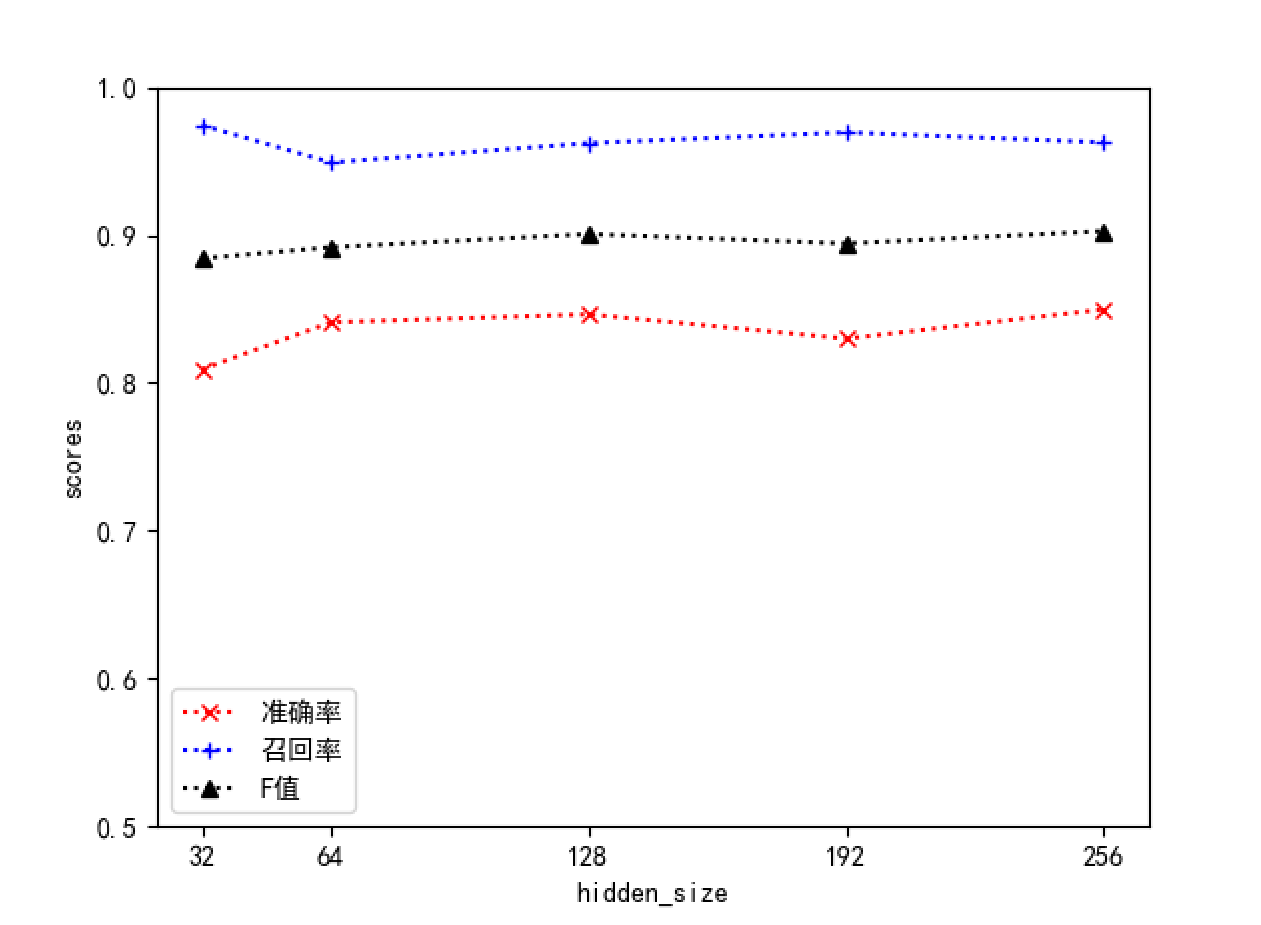
从结果中可以看出,随着h值的增大,准确率提高,召回率下降,F值无明显变化;num_layers则在为2值表现出的性能更加均衡;增加hidden_size的值,各项指标都有一定的上升趋势,但是趋势不是很明显。由于增大h值、num_layers或者hidden_size会提高模型的复杂度,导致训练周期和系统开销增大,综合来看我们选择h=10,num_layers=2和hidden_size=64作为基准参数,能够取得较好的性能。
本文测试阶段的代码已上传到了 https://github.com/saucer-man/Dlog
5. 总结
在Deeplog中比较重要的工作流模型没有体现,实际上我们的检测都是在同一个进程产生的日志基础上来做的,如果不同进程产生的日志相互交织,从而导致执行路径交错,检测误差较大。这一点是比较难的点。
我只是在收集日志时做了进程区分,在检测阶段并没有实现工作任务流区分,有兴趣的童鞋可以看看Deeplog。
用预测日志顺序来做异常检测感觉不是很靠谱,感觉应用面不大
请教个问题:训练后train模型需要定期更新吗?还是比方说我取一段时间的历史数据作为train训练处模型,后续一致用这个模型预测,如果要更新模型,大概多久一次比较合适呢?
index.py里面
train_log_file = "logdata/Linux/train.log"
test_log_file = "logdata/Linux/train.log"
这部分为什么test和train都是读取的train.log?,第二个换成test.log会报错。
@新樽旧月 不好意思,已经不再研究此方向,文章内容仅作参考,此贴不再回复
您好,很荣幸拜读您的关于DeepLog的文章,我是这方面的初学者,我在下载您的代码试着跑了一下,在deeplog文件下的代码训练之后等了好久没后后续,一直运行但是没有结果,请问您运行大约多久呀?
@陈Sir 你好,请问你这代码运行顺序是什么
@SwordMan 请问您现在运行成功了么?大概多长时间?我目前也是遇到这个问题
@SwordMan 我运行的deeplog文件夹下analyse文件夹的train文件,epoches迭代完成了,但是后面就没有结果,一直没显示。
同学 您好,我想问下 那个hdfs的序列 是怎么得到?错误序列在哪里找呢?谢谢
@csq 通过日志键id(事件编号)构建
@csq 抱歉具体的细节我已经忘了,你看看https://github.com/wuyifan18/DeepLog/issues这里,就知道答案了
@saucerman 好的,谢谢
同学你好,请问:日志解析时,匹配的日志键。那如果后来的日志匹配上最前的日志键,那不是打乱了日志的执行顺序吗,怎么根据日志键的序列进行检测呢
@shanshan 后来的日志匹配上最前的日志键.就代表这条日志属于这个日志键,才构成一条日志键的执行顺序亚
同学你好,谢谢你的分享,我想请教你一下,这篇论文没有对日志的异常进行具体的分类吗?比如把异常分为用户行为异常,流量异常等?
@TZL 我记得是没有的
同学你好,这篇文章中提到的通过合并实时用户反馈来在检测阶段逐步更新其权重的功能,你有了解嘛
@zizi 没了解过..
感谢你的分享,帮我解决了一些困惑!
同学你好,最近也在研究这篇论文
加入dropout为什么能够改进lstm呢?
@jkl 没有说一定能改进,一定情况下加上可能有效果(当然也可能拖慢速度 准确率低)。得自己试试吧~
@saucerman 哈哈说的也是,不过最近突发奇想想用transformer代替原文的lstm试一试,毕竟原模型没有考虑预测时目标对“后文”的依赖嘛,您觉得这样做合理吗?^_^
@jkl 听起来很可行,GRU、RNN都可以试试,感觉很取决于日志数据。