对于XSS攻击的绕过姿势,大家可能张口就来利用编码,但是编码方式那么多种,该怎么去编码,其又是什么原理,可能大部分人并不熟悉,这次借着这篇文章来探索一下XSS编码绕过姿势和原理,如有错误,欢迎指正。
0x01 认识请求网页的解码过程
编码属于计算机系统的基础知识,其内容写起来估计也可以出本书了,不过或多或少我们都有所了解,总的来说,编码就是将字符变为二进制数,而解码就是还原二进制数为字符。从浏览器请求url到在页面上显示出来也经历了一些编码和解码过程,下面大概介绍一下流程。具体的过程可参考这里
URL编码
URL编码是为了允许URL中存在汉字这样的非标准字符,本质是把一个字符转为%加上UTF-8编码对应的16进制数字。所以又称之为Percent-encoding。
在服务端接收到请求时,会自动对请求进行一次URL解码。
HTML编码/解码
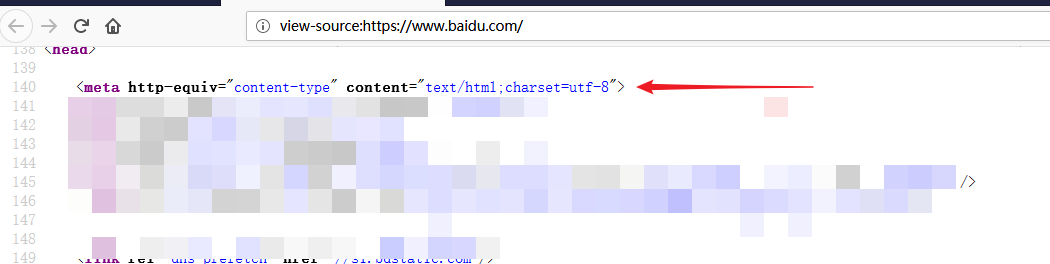
当浏览器接收到服务端发送来的二进制数据后,首先会对其进行HTML解码,呈现出来的就是我们看到的源代码。具体的解码方式依具体情况而定,所以我们需要在页面中指定编码,防止浏览器按照错误的方式解码,造成乱码,比如百度搜索首页就指定了解码方式为UTF-8:(为了找到重点,对其余地方打码)
但是在HTML中有些字符是和关键词冲突的,比如
<、>、&,解码之后,浏览器会误认为它们是标签,怎么解决呢?为了正确地显示预留字符,我们需要在HTML源代码中使用字符实体,比如我们常见的空格
,字符实体以&开头+预先定义的实体名称表示,但不是所有的字符都有实体名称,但是它们都有实体编号,也可以用&#开头+实体编号+分号表示。比如:
| 显示结果 | 描述 | 实体名称 | 实体编号 |
|---|---|---|---|
< | 小于号 | < | < |
> | 大于号 | > | > |
浏览器对HTML解码之后就开始解析HTML,将标签转化为内容树中的DOM节点,此时识别标签的时候,HTML解析器是无法识别那些被实体编码的内容的,只有建立起DOM树,才能对每个节点的内容进行识别,如果出现实体编码,则会进行实体解码,只要是DOM节点里属性的值,都可以被HTML编码和解析。
所以在PHP中,使用htmlspecialchars()函数把预定义的字符转换为HTML实体,只有等到DOM树建立起来后,才会解析HTML实体,起到了XSS防护作用。
JS解码(只支持UNICODE)
当HTML解析产生DOM节点后,会根据DOM节点来做接下来的解析工作,比如在处理诸如
<script> <style>这样的标签,解析器会自动切换到JS解析模式,而src、href后边加入的javascript 伪URL,也会进入JS 的解析模式。比如
<a href="javascript:alert('<\u4e00>')">test</a>,javascript 出发了JS 解释器,JS会先对内容进行解析,里边有一个转义字符\u4e00,前导的 \u 表示他是一个unicode 字符,根据后边的数字,解析为一,于是在完成JS的解析之后变成了:href="javascript:alert('<一>')">test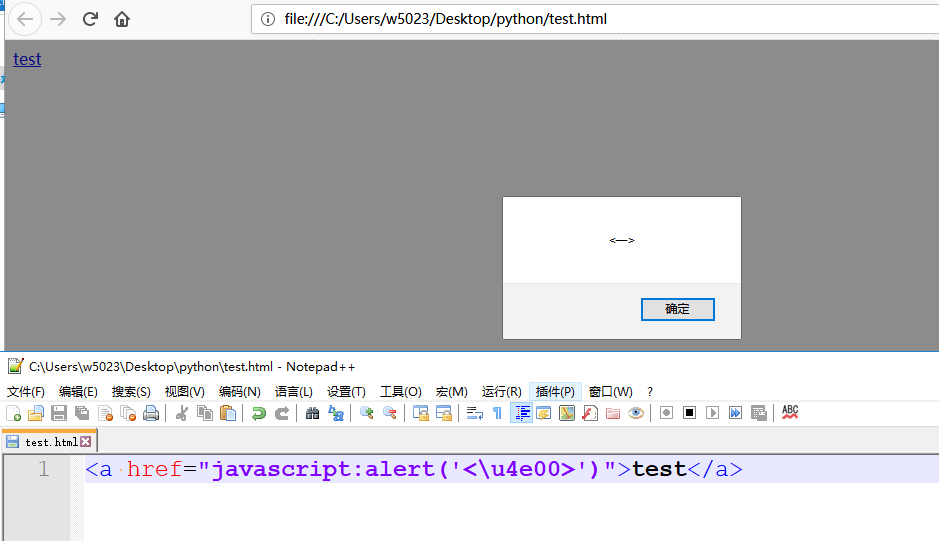
由此可见,想要字符编码后能够被JS识别,可以对字符进行unicode编码。
0x02 XSS编码实践
先用一个普通的XSS代码来做说明 <a href="javascript:alert('xss')">test</a>,浏览器对其解析的过程大致为:
首先HTML解析器开始工作,并对href中的字符做HTML解码,接下来URL解析器对href值进行解码,正常情况下URL值为一个正常的URL链接,如:https://www.baidu.com,那么URL解析器工作完成后是不需要其他解码的,但是该环境中URL资源类型为Javascript,因此该环境中最后一步Javascript解析器还会进行解码操作,最后解析的脚本被执行。
整个解析顺序为3个环节:HTML解码 –>URL解码 –>JS解码
我们可以对其做以下变形,下列情况都可以成功弹框:
- 将
javascript:alert('xss')转化为HTML实体,因为解析HTML之后,建立起<a>DOM节点,然后对DOM节点里面的HTML实体进行解析。
<a href="javascript:alert('xss')">test</a>
- 对
alert做JS编码,因为当HTML打算对<a>DOM节点进行HTML实体解析时,发现URL资源类型为Javascript,因此会调用JS解析器来对JS代码进行解析
<a href="javascript:\u0061\u006c\u0065\u0072\u0074('xss')">test</a>
- 也可以利用解码顺序进行混合编码:
1. 原代码
<a href="javascript:alert('xss')">test</a>
2. 对alert进行JS编码(unicode编码)
<a href="javascript:\u0061\u006c\u0065\u0072\u0074('xss')">test</a>
3. 对href标签中的\u0061\u006c\u0065\u0072\u0074进行URL编码
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34('xss')">test</a>
4. 对href标签中的javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34('xss')进行HTML编码:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34('xss')">test</a>
怎么样?经过三种编码都可以弹框,是不是觉得顿时有点懵?在这里最好亲自动手试试能否弹框。
问题来了,既然浏览器会对href的里面的链接做一次URL解码,是否可以对href里面的内容整体做一次URL编码:
<a href="javascript:alert('xss')">test</a>
对href里面的javascript:alert('xss')做一次URL编码:
<a href="%6a%61%76%61%73%63%72%69%70%74%3a%61%6c%65%72%74%28%27%78%73%73%27%29">test</a>
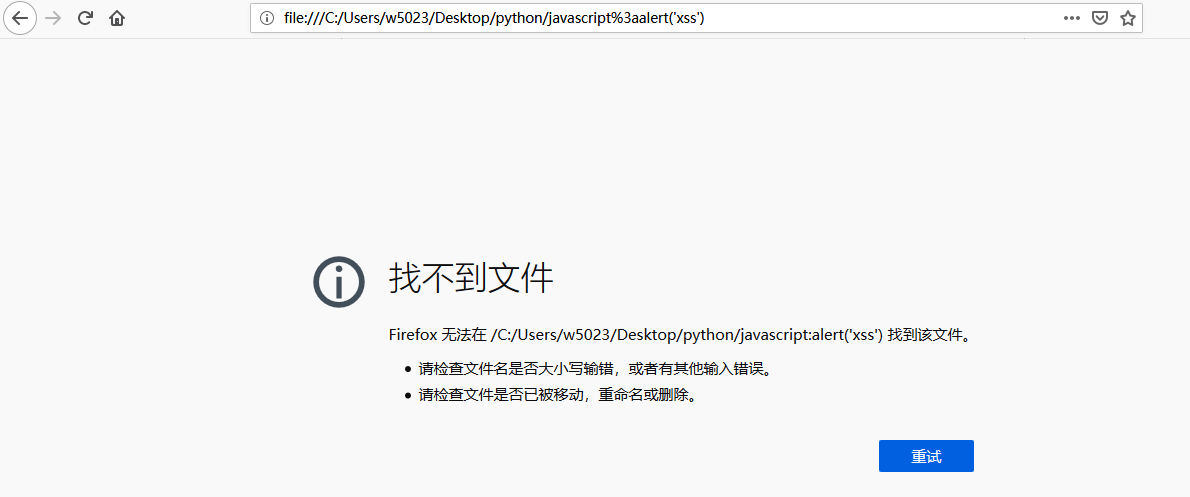
上面的实验结果表示这样并不可行,这里就有一个URL解析过程中的一个细节了,不能对协议类型进行任何的编码操作,否则URL解析器会认为它无类型,就导致上面DOM节点中被编码的“javascript”没有解码,当然不会被URL解析器识别了。就比如说http://www.baidu.com可以被编码为http://%77%77%77%2e%62%61%69%64%75%2e%63%6f%6d,但是不能把协议也编码了:%68%74%74%70%3a%2f%2f%77%77%77%2e%62%61%69%64%75%2e%63%6f%6d
和上面解析情况类似的XSS代码为:
<img src=xxx onerror="javascript:alert(1)">
对其稍作变形可得到:
1. 对javascript:alert(1)进行HTML编码
<img src=xxx onerror="javascript:alert(1)">
2. 对alert进行JS编码
<img src=xxx onerror="javascript:\u0061\u006c\u0065\u0072\u0074(1)">
3. 以上两种方法混用
<img src=xxx onerror="javascript:\u0061\u006c\u0065\u0072\u0074(1)">
再试试我们的终极大杀器
<script>alert(1)</script>
对其进行编码:
1. 对alert进行JS编码
<script>\u0061\u006c\u0065\u0072\u0074(1)</script>
注意:这里是不能对alert(1)进行HTML编码的,因为HTML解析时发现这个DOM节点是script,会调用JS解析来解析其中的内容。但是有个小技巧为:
<svg><script>alert('xss')</script>
还有个小细节:
对于刚才JS编码时,我们只编码了alert('xss')中的alert,这里我们能不能一起都编码呢?答案是不能。在进行JavaScript解析的时候字符或者字符串仅会被解码为字符串文本或者标识符名称,在上例中Javascript解析器工作的时候将\u0061\u006c\u0065\u0072\u0074进行解码后为alert,而alert是一个有效的标识符名称,它是能被正常解析的。像圆括号、双引号、单引号等等这些字符就只能被当作普通的文本,从而导致无法执行,比如<script>alert('aaa\u0027)</script>解析后缺少闭合的单引号而无法执行成功。
关于XSS编码的内容就这么多,总之学习任何知识都需要理解原理,回头看看,总能会发现自己不会的点。