写在开头:eBPF体系逐渐成熟,应用愈加广泛,所以计划一边学习一边写写eBPF的相关内容,本文为eBPF的介绍,将会涉及到eBPF的含义和来源,并编写一个最简单的eBPF程序。如有错误,欢迎指正。
1. 发展历程
1.1 LKM
在Linux的体系结构中,内存分为内核空间和用户空间。内核空间用于运行核心内核代码和设备驱动程序。在内核空间中运行的进程可以不受限制地访问所有硬件,包括CPU、内存和磁盘等。其他进程都在用户空间中运行,用户空间的进程一般是通过系统调用与内核通信来访问系统硬件,例如,要发送网络数据包,用户空间应用程序必须通过系统调用与内核空间网卡驱动程序进行通信,最终的数据由网卡驱动程序发送出去。
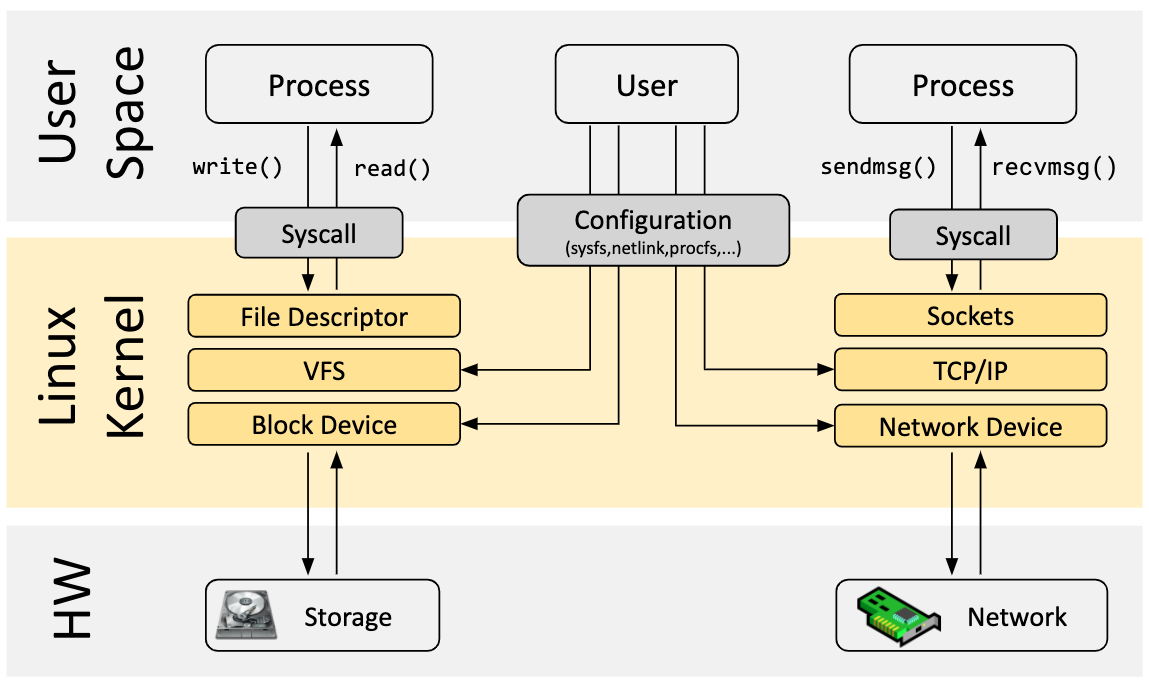
这种空间分离机制保障了linux的安全性,比如可以在内核空间引入一系列安全信任链等等,但是也带来很多不便携性,比如用户想去修改内核代码或者拓展系统的硬件接口,那就没啥好办法,只好自己重新编译内核,成本很高。于是Linux提供了Linux Kernel Modules,简称为LKM,就是内核模块,可以在运行时按需直接加载到内核中,之前常见的rootkit就是这么操作的:写个内核模块作为后门,并且在模块中同时hook ls、ps等命令来达到隐藏自己的效果。
LKM看似很好,可以在运行时加载,从而无需重新编译整个内核,但是这种方式也同时带来了风险,当你无意间写了一个bug,会造成系统奔溃,总之就是用起来不太安全。在2014年初,eBPF(extended Berkeley Packet Filter)诞生了,eBPF是由BPF(Berkeley Packet Filter 也称为CBPF)演化而来。下面先来介绍下BPF
1.2 BPF
BPF(Berkeley Packet Filter)伯克利包过滤器,最初构想提出于1992年5,其发明原因是为了处理庞大的系统流量的,因为在用户空间去做流量的过滤,需要系统将流量数据从内核空间复制到用户空间,会造成巨大的性能开销。本质上BPF也是一种对内核代码的扩展,在Linux内核中,BPF的实现主要依赖于两个部分:一是内核空间中的BPF虚拟机,二是内核空间中的BPF过滤器。
BPF虚拟机:BPF虚拟机是一个用于执行BPF字节码的内核模块,它能够高效地解释和执行用户定义的BPF程序。当用户传递给内核一个BPF字节码文件时,BPF虚拟机就会把这个字节码文件加载到内核空间中,并在内核空间中执行这个BPF程序。 BPF过滤器:BPF过滤器是一个内核模块,它能够在数据包在网络上传输时自动过滤这些数据包。BPF过滤器会把数据包传递给BPF虚拟机,由BPF虚拟机根据用户定义的过滤规则来过滤数据包。如果数据包符合过滤规则,就会将其转发到目标主机,否则就会丢弃这些数据包。
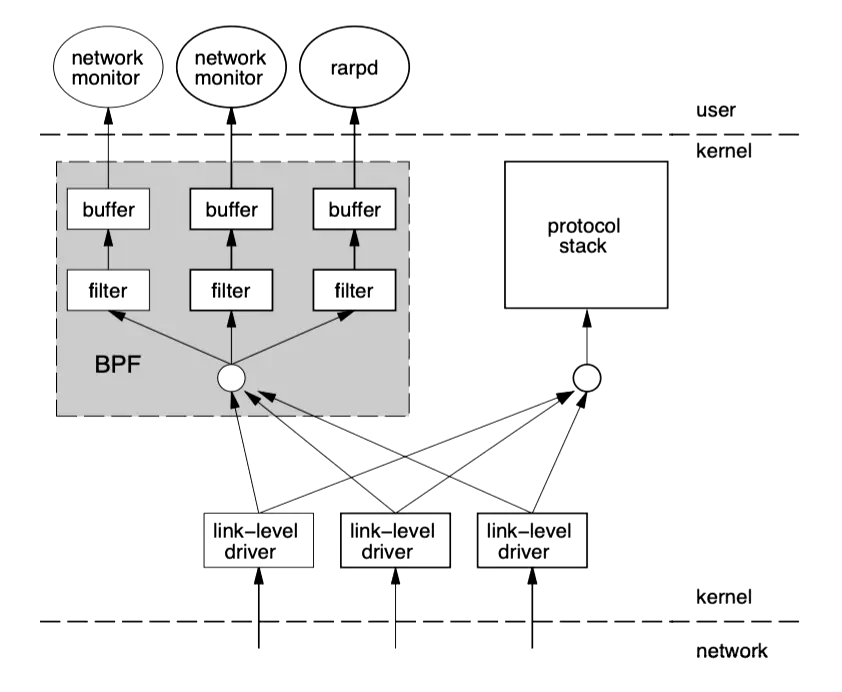
同时BPF虚拟机中会对运行的代码进行检查,确保不会发生系统奔溃,最有名的BPF程序就是tcpdump。
1.3 eBPF
通过BPF的实现,在内核中运行自定义的指令成为可能,2014年,Linux 3.18中提供了扩展的BPF,即eBPF,在linux 4.14中功能才比较完整。和cBPF相比,eBPF主要具有以下改进:
- 从32位寄存器改进到64位寄存器,并将寄存器的数量从两个增加到十个
- 提供了改进的指令集,扩展了指令,提高了性能
- 增加了程序大小,eBPF程序栈空间最多可用512字节,且可以通过map进行数据存储传递
下面介绍下eBPF程序的运行流程5
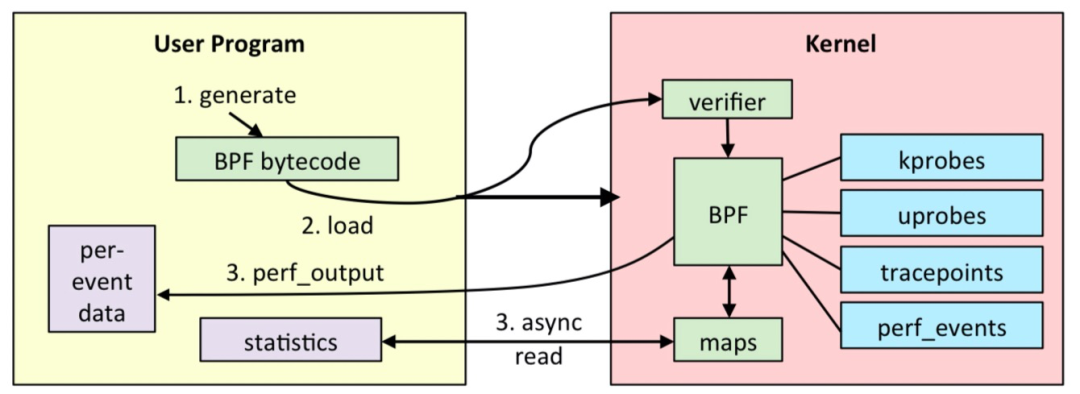
- 在用户空间编写C代码,并将其编译eBPF程序,形成eBPF字节码,这一步我们可以直接使用Clang/LLVM来编译即可。
- 通过bpf系统调用,把eBPF字节码提交给内核;
- 内核中的eBPF验证程序,对字节码运行多项安全检查,以确保程序的安全性。
- 验证完毕后,eBPF字节码被JIT编译成本地机器码,然后被附加到内核中由指定事件触发的hook点
- 当指定的事件发生时,程序被执行并将数据写入maps。
- 用户空间的程序通过maps,与内核空间的程序进行通信,得到执行日志。
1.4 ebpf vs LKM
来自4
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
1.5 ebpf的应用场景
目前eBPF已经覆盖了很多的应用场景,主要包括网络流量控制、内核监测和安全三个方向。更多的使用案例可以参考:https://ebpf.io/case-studies
1.5.1 网络流量控制
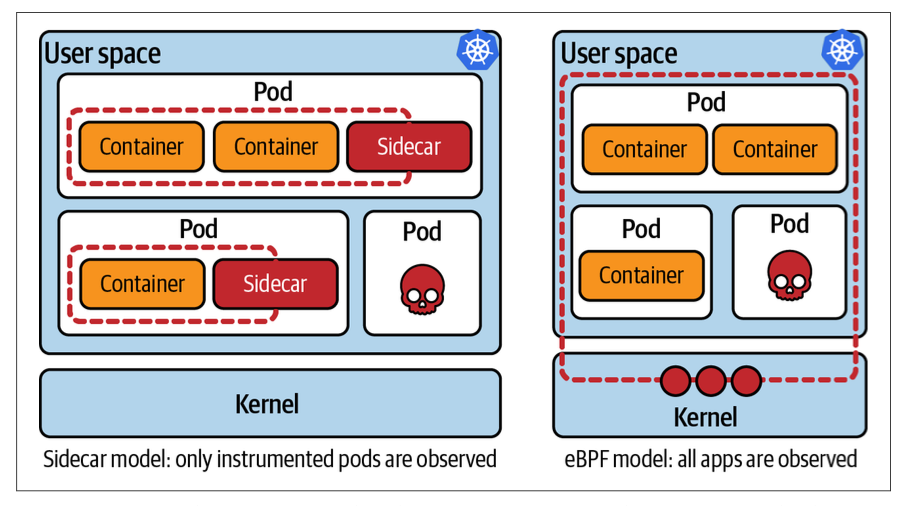
eBPF可以用于在内核中过滤网络数据包,以实现防火墙、网络流量控制和数据包转发等功能。此外eBPF在云原生的场景中已经有了很多应用,比如eBPF可以在Docker或Kubernetes等容器环境中实施安全策略,因为容器环境依赖于宿主机的内核,所以只要在内核中布置一些流量策略和安全监测,那么就可以应用到所有的容器中,就不再需要对每个容器进行单独监测,下图反应了使用eBPF前后的对比8
eBPF还常常结合XDP(eXpress Data Path)来实现一些高性能的网络控制模块。举个例子,Cloudflare使用eBPF+XDP,如果数据包被识别为可疑来源,则丢弃此数据包,从而实现DDos的过滤,可见他们的开源项目 https://github.com/cloudflare/rakelimit
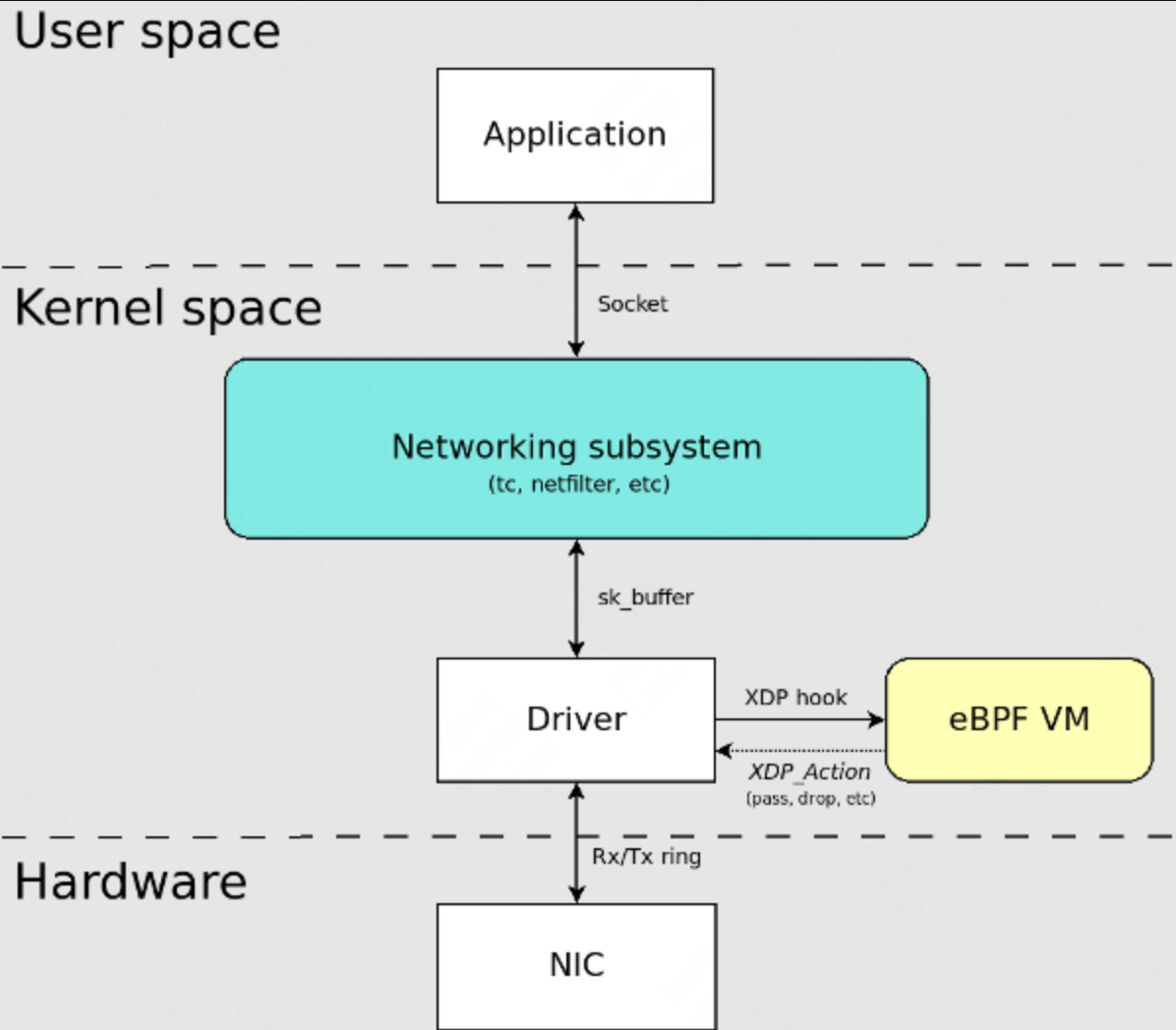
1.5.2 内核监测
在bcc工具集中包含了各种使用eBPF技术编写的监测工具,可以用来监测内存、cpu、网络连接等等,还可以用来跟踪内核的执行流程,包括内核函数的调用、内存分配情况和中断处理等,这些信息可以用于排查问题和优化内核的性能。
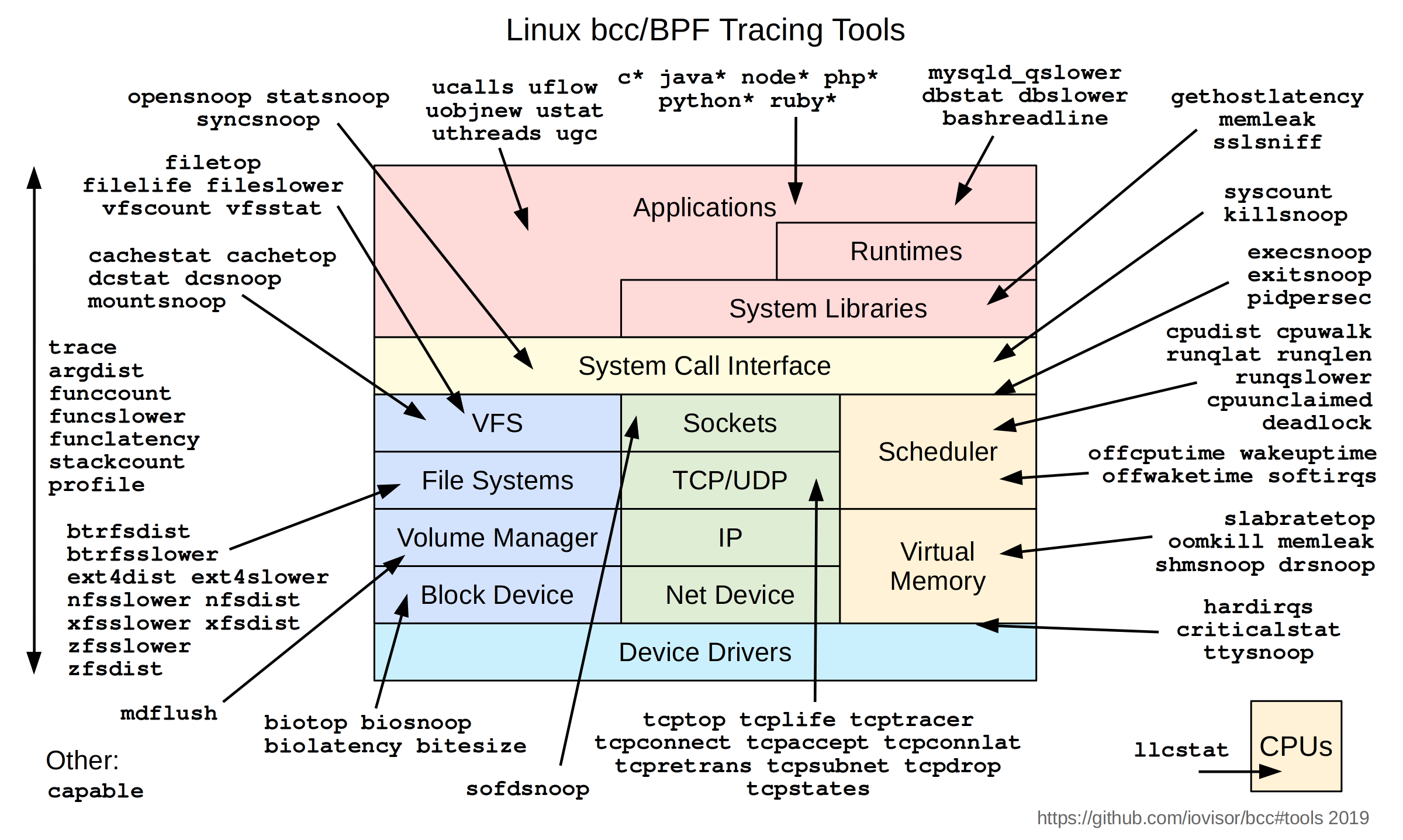
1.5.3 安全
在安全中的应用其实不算新的领域,其原理也主要是结合了网络流量控制和内核监测功能。目前在安全上的领域大概有以下几个方向:
- 利用系统监测能力,来保障程序的运行时安全(还有nids之类的主机安全系统)
- 利用网络流量控制能力,来实现防火墙、云原生安全等(还有最近很火的ecapture,可以实现无ssl证书抓包)
- 对应用进行全方位的trace,从而实现逆向和分析
2. eBPF程序编写
在前文提到了,我们需要eBPF字节码,并且将字节码附加到内核中,字节码就类似于汇编语言,显然直接编写eBPF字节码是不现实的,所以现在的常见做法是用C语言来写eBPF程序(现在也可以使用rust),然后利用LLVM clang编译器将其编译成eBPF字节码。编译完之后,将字节码附加到内核中有比较多的工具、不同的语言去实现,比如bcc、aya、libbpfgo等等。但是大道至简,原理类似,下面我们将通过bcc框架编写一个简单的eBPF程序。
2.1 bcc是什么
BCC是一个eBPF前端框架, 能够让用户编写嵌入了eBPF程序的python程序。该工具包包含以下功能:
- 加载并使用LLVM clang编译eBPF C代码
- 加载eBPF字节码到内核hook点,比如socket filters, tc classifiers, tc actions, kprobes
- 绑定python语言,比如可以使用python来通过maps与eBPF程序进行通信
2.2 安装bcc工具集
参考https://github.com/iovisor/bcc/blob/master/INSTALL.md ,在ubuntu20上通过编译安装,如果直接使用apt安装的话,大概率会有问题。
# 先安装系统依赖
sudo apt install -y bison build-essential cmake flex git libedit-dev \
libllvm12 llvm-12-dev libclang-12-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
然后下载源代码编译
git clone https://github.com/iovisor/bcc.git
mkdir bcc/build; cd bcc/build
cmake ..
make
sudo make install
cmake -DPYTHON_CMD=python3 .. # build python3 binding
pushd src/python/
make
sudo make install
popd
然后我们运行下面的工具来测试是否安装成功
/usr/share/bcc/tools/execsnoop
如果出现错误 No module named bcc 的话,那是因为默认的python还是python2,这里我直接修改软链接即可
# 参考 https://stackoverflow.com/questions/65043495/what-should-i-do-if-sudo-usr-share-bcc-tools-execsnoop-fails-after-build-bcc
ls -l `which python`
rm /usr/bin/python
sudo ln -s /usr/bin/python3 /usr/bin/python
安装完毕后,在/usr/share/bcc/tools/中保存着使用eBPF编写的各种工具,各种工具的用法和功能可以参考https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
下面演示下execsnoop工具的效果,execsnoop是专门用于为追踪短时进程(瞬时进程)设计的工具,它通过ftrace实时监控进程的exec() 行为,并输出短时进程的基本信息,包括进程PID、父进程PID、命令行参数以及执行的结果,类似于history,可以帮助排查性能问题。
root@ubuntu:~/bcc# /usr/share/bcc/tools/execsnoop -h
usage: execsnoop [-h] [-T] [-t] [-x] [--cgroupmap CGROUPMAP] [--mntnsmap MNTNSMAP] [-u USER] [-q] [-n NAME] [-l LINE] [-U] [--max-args MAX_ARGS] [-P PPID]
Trace exec() syscalls
optional arguments:
-h, --help show this help message and exit
-T, --time include time column on output (HH:MM:SS)
-t, --timestamp include timestamp on output
-x, --fails include failed exec()s
--cgroupmap CGROUPMAP
trace cgroups in this BPF map only
--mntnsmap MNTNSMAP trace mount namespaces in this BPF map only
-u USER, --uid USER trace this UID only
-q, --quote Add quotemarks (") around arguments.
-n NAME, --name NAME only print commands matching this name (regex), any arg
-l LINE, --line LINE only print commands where arg contains this line (regex)
-U, --print-uid print UID column
--max-args MAX_ARGS maximum number of arguments parsed and displayed, defaults to 20
-P PPID, --ppid PPID trace this parent PID only
examples:
./execsnoop # trace all exec() syscalls
./execsnoop -x # include failed exec()s
./execsnoop -T # include time (HH:MM:SS)
./execsnoop -P 181 # only trace new processes whose parent PID is 181
./execsnoop -U # include UID
./execsnoop -u 1000 # only trace UID 1000
./execsnoop -u user # get user UID and trace only them
./execsnoop -t # include timestamps
./execsnoop -q # add "quotemarks" around arguments
./execsnoop -n main # only print command lines containing "main"
./execsnoop -l tpkg # only print command where arguments contains "tpkg"
./execsnoop --cgroupmap mappath # only trace cgroups in this BPF map
./execsnoop --mntnsmap mappath # only trace mount namespaces in the map

2.3 使用bcc编写ebpf程序
下面来尝试写一个bcc程序,注意:要编写bcc工具首先要安装bcc工具环境,这也是bcc的一个不便之处。
首先我们创建一个htlloworld.py文件,所有的代码都在这个py文件里面编写完成
首先需要导入BPF库
from bcc import BPF
然后编写eBPF的C代码,这里我们直接将其写在python程序中,存储为一个字符串变量。
program = """
int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
这里定义了一个名为kprobe__sys_clone的函数,下面来解释下这段C代码:
- kprobe__sys_clone: 这个函数名称是有含义的,这个名称声明自己将用于监听内核中的sys_clone系统调用,这是一种通过kprobes[9]进行内核hook的方式。(kprobe是内核提供的代码跟踪工具,允许你在任何内核位置动态打断并收集调试信息)
- void *ctx: 这个参数实际上是struct pt_regs *类型,包含寄存器和eBPF的上下文。由于我们没有在这里使用它,所以将它转换为void *。
- bpf_trace_printk:这是eBPF中的一个函数,意思是将字符串printf到trace_pipe文件中(/sys/kernel/debug/tracing/trace_pipe),trace_pipe是Linux内核中的一个特殊的文件,它提供了一种通过文件读写操作访问内核跟踪数据的方式。通过trace_pipe文件,用户态程序可以读取内核跟踪数据,并使用相应的工具进行分析和处理。
- return 0: 告诉kprobe框架,在执行完此eBPF程序后,立刻返回,是一个必要的写法
然后在bcc中编译该程序,并把字节码加载到内核中
b = BPF(text=program)
然后读取linux内核的trace_pipe,trace_field函数在trace_pipe上执行阻塞读取,读取到的字段为固定格式的信息。然后将读取到的信息打印出来
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMMAND", "PID", "MESSAGE"))
while True:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
print("%-18s %-16s %-6d %s" % (ts, task.decode(), pid, msg.decode()))
except ValueError:
continue
最终完整的代码如下
#!/usr/bin/python
# run in project examples directory with:
# sudo ./hello_world.py"
from bcc import BPF
program = """
int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
b = BPF(text=program)
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMMAND", "PID", "MESSAGE"))
while True:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
print("%-18s %-16s %-6d %s" % (ts, task.decode(), pid, msg.decode()))
except ValueError:
continue
执行结果如下
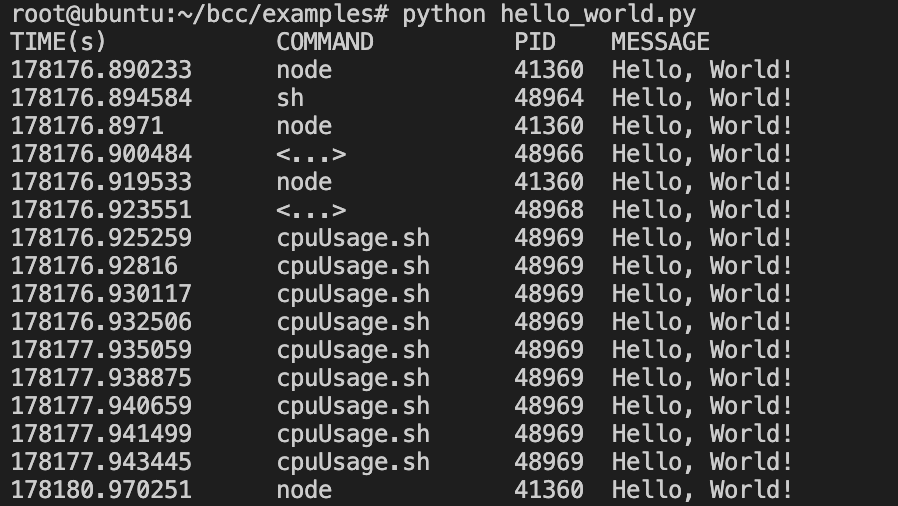
到这里第一个eBPF程序就完成了。
使用bcc的缺点是程序分发比较麻烦,因为使用bcc写的程序在python代码运行时才会对eBPF C程序执行编译、加载、运行,依赖于其内置的Clang/LLVM编译器,所以分发程序时,还得带上Clang/LLVM这个庞大的库,且依赖于特定的内核头文件,针对这个问题目前也已经有了解决方案BPF CO-RE,如果不出意外这些内容将会在后面的文章中介绍。
3. 参考
1 https://www.containiq.com/post/ebpf 2 https://www.infoq.com/articles/gentle-linux-ebpf-introduction/ 3 http://derekmolloy.ie/writing-a-linux-kernel-module-part-1-introduction/ 4 https://cloudnative.to/blog/bpf-intro/ 5 https://www.51cto.com/article/711018.html 6 https://www.tcpdump.org/papers/bpf-usenix93.pdf 7 https://ebpf.io/what-is-ebpf 8 https://www.ebpf.top/what-is-ebpf/content/5.ebpf-in-cloud-native-environments.html [9] http://linux.laoqinren.net/kernel/linux-kprobe/ [10] https://github.com/iovisor/bcc