最近比较高强度使用codex,但是对codex的很多功能实现方式有所疑问,所以基于20260623版本的codex做一下分析,主要是进行了抓包和源代码分析
1. 一个agent的基本构成
在了解codex之前,先需要了解下什么是agent,在大模型刚出来时,调用llm通常就是简单的请求服务端获取响应,比如
import os
import requests
response = requests.post(
"https://api.openai.com/v1/responses",
headers={
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}",
"Content-Type": "application/json",
},
json={
"model": "gpt-5.5",
"input": "hello",
},
timeout=60,
)
response.raise_for_status()
data = response.json()
print(data["output"][0]["content"][0]["text"])
早期AI应用比如文案生成器就是这么实现,后来为了让llm发挥更多能力,出现了React(Reasoning and Acting)Agent,这是一种基于推理-行动循环的智能代理模式。与传统的单次问答不同,实现流程如下:
- 用户提出任务
- LLM 分析当前信息,决定调用哪个工具及参数
- Agent 执行工具
- 将工具结果作为
Observation放回上下文 - LLM结合新信息继续判断
- 达到目标或最大轮数后输出答案
代码实现如下
import json
import os
import requests
API_URL = "https://api.openai.com/v1/responses"
API_KEY = os.environ["OPENAI_API_KEY"]
def calculate(expression):
# 示例代码,生产环境不要直接 eval 不可信输入
return str(eval(expression, {"__builtins__": {}}, {}))
TOOLS = {
"calculate": calculate,
}
def call_llm(messages):
response = requests.post(
API_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
json={
"model": "gpt-5.5",
"input": messages,
},
timeout=60,
)
response.raise_for_status()
data = response.json()
return data["output"][0]["content"][0]["text"]
def run_agent(question, max_steps=5):
messages = [
{
"role": "developer",
"content": """
你是一个 ReAct Agent。
每次只返回一个 JSON 对象:
调用工具:
{"type":"action","tool":"calculate","arguments":{"expression":"1+1"}}
直接回答:
{"type":"final","answer":"最终答案"}
不要输出 JSON 之外的内容。
""",
},
{"role": "user", "content": question},
]
for _ in range(max_steps):
result = json.loads(call_llm(messages))
if result["type"] == "final":
return result["answer"]
tool_name = result["tool"]
arguments = result["arguments"]
if tool_name not in TOOLS:
observation = f"未知工具:{tool_name}"
else:
try:
observation = TOOLS[tool_name](**arguments)
except Exception as exc:
observation = f"工具执行失败:{exc}"
messages.append({
"role": "assistant",
"content": json.dumps(result, ensure_ascii=False),
})
messages.append({
"role": "user",
"content": f"Observation: {observation}",
})
raise RuntimeError("Agent 超过最大执行轮数")
print(run_agent("计算 (18 + 24) * 3"))
实际执行时如下:
用户:计算 (18 + 24) * 3
模型:调用 calculate
工具:返回 126
模型:根据 Observation 输出最终答案
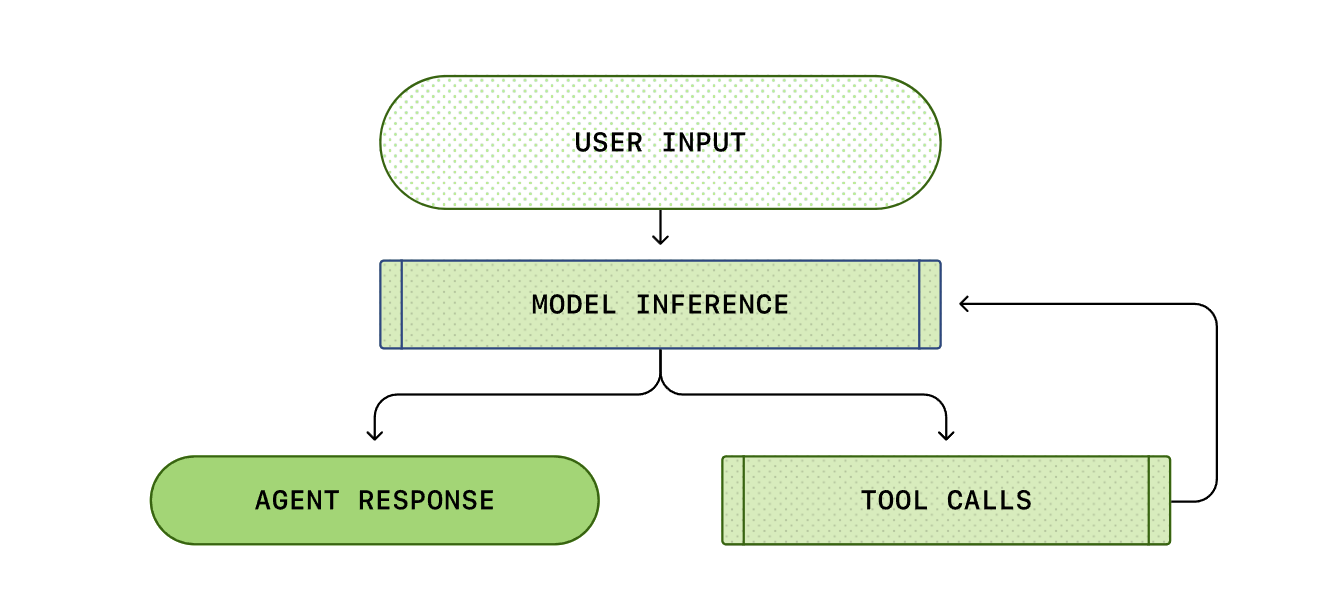
再后来agent开发有了个专业名词叫harness engineering,在React架构的基础上添加了更多功能,现在的agent有下列一些组件:
| 组件 | 作用 |
|---|---|
| 模型 | 理解任务、推理并决定下一步 |
| Agent Loop | 循环执行“思考 → 行动 → 观察” |
| 上下文 | 保存对话、文件内容和执行结果 |
| 工具 | 读写文件、执行命令、搜索代码、运行测试 |
| 执行环境 | Workspace、Shell、Git、沙箱 |
| 扩展与安全 | Skills、MCP、子 Agent、权限审批 |
2. openai官方API
codex功能很复杂,所以可以从客户端和服务端的网络交互来解析原理,现在的openai request中已经不止只有一个prompt了,还带上了更多参数,官方API文档为:https://developers.openai.com/api/reference/resources/responses/methods/create
基础参数
| 参数 | 类型 | 说明 |
|---|---|---|
model | string | 模型 ID,如 gpt-5.5 |
input | string / array | 用户输入,可以是文本、消息、图片、文件或工具结果 |
instructions | string | 最高优先级的系统/开发者指令 |
max_output_tokens | number | 最大生成 Token 数,包含可见文本和推理 Token |
metadata | object | 最多 16 个键值对;键最长 64,值最长 512 字符 |
store | boolean | 是否保存 Response,便于之后通过 ID 查询 |
上下文与会话
| 参数 | 说明 |
|---|---|
previous_response_id | 上一次 Response ID,用于简单的连续对话 |
conversation | Conversation ID;请求输入和输出会自动加入该会话 |
context_management | 上下文管理配置,目前支持自动压缩 compaction |
truncation | disabled:超长时报错;auto:丢弃最早内容以适配窗口 |
生成控制
| 参数 | 取值 | 说明 |
|---|---|---|
temperature | 0~2 | 越低越稳定,越高越随机 |
top_p | 0~1 | 核采样范围;通常不要和 temperature 同时调整 |
top_logprobs | 0~20 | 返回每个位置概率最高的若干 Token |
reasoning | object | 控制推理强度和推理摘要 |
text | object | 控制文本格式、JSON Schema 和详细程度 |
工具参数
| 参数 | 说明 |
|---|---|
tools | 声明模型可以调用的工具 |
tool_choice | 控制是否以及必须调用哪个工具 |
parallel_tool_calls | 是否允许并行调用多个工具 |
max_tool_calls | 一次 Response 最多处理多少次内置工具调用 |
3. codex请求包分析
在一个干净的上下文环境中,让codex读取文件D:/1.txt的内容并打印出来,到执行结束一共有3个请求包,这 3 个请求都是 POST /responses:
请求 1:主任务首轮推理,模型决定调用 shell_command
请求 2:并行生成会话标题,使用 JSON Schema 强制只返回 title
请求 3:主任务工具调用后的续轮推理,把工具调用及结果重新放入 input,生成最终回答
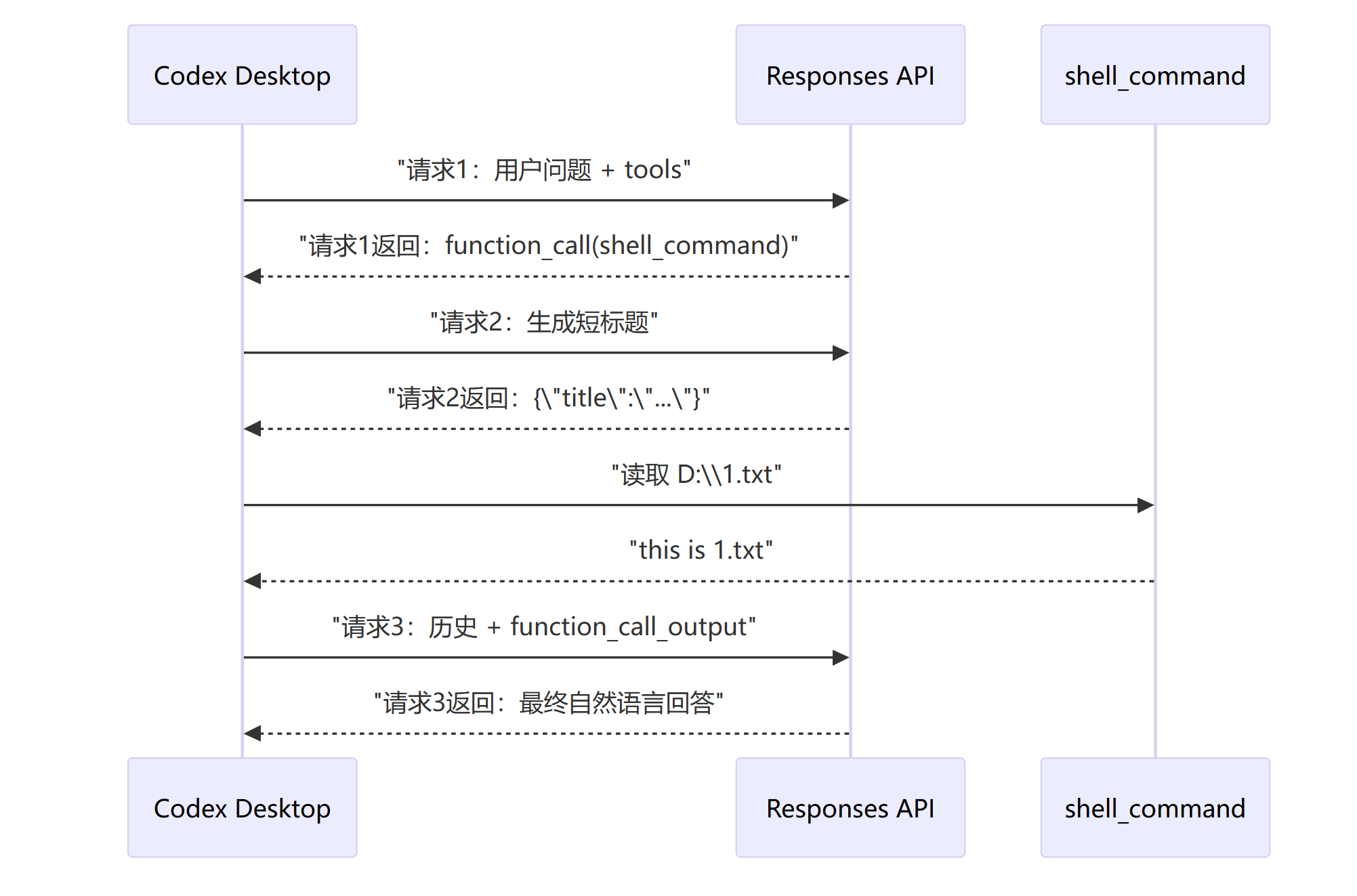
请求 1、3 属于同一个 thread_id / turn_id;请求 2 是独立线程的辅助请求。
3.1 请求头
| 请求头 | 含义 | API 标准 |
|---|---|---|
Authorization: Bearer ... | 身份认证 | 是 |
Content-Type: application/json | JSON 请求体 | 是 |
Accept: text/event-stream | 接收 SSE 流 | 配合 stream=true |
User-Agent | Codex Desktop 版本、系统信息 | HTTP 客户端字段 |
originator: Codex Desktop | 请求来源产品 | Codex 私有扩展 |
x-client-request-id | 客户端请求追踪 ID | Codex 私有扩展 |
session-id | Codex 会话 ID | Codex 私有扩展 |
thread-id | Codex 线程 ID | Codex 私有扩展 |
x-codex-window-id | Desktop 窗口 ID | Codex 私有扩展 |
x-codex-turn-metadata | 安装、会话、线程、轮次、沙箱等信息 | Codex 私有扩展 |
x-codex-beta-features | 启用的实验功能 | Codex 私有扩展 |
3.2 请求体
请求体字段如下

| 字段 | 实际值/结构 | 含义 |
|---|---|---|
model | "gpt-5.5" | 使用的模型 |
instructions | 21460 字符 | Codex 基础系统提示词;对应 API 的系统/开发者指令 |
input | 3 项 | 本轮输入上下文 |
tools | 16 项 | 模型可调用的工具定义 |
tool_choice | "auto" | 模型自行决定回答或调用工具 |
parallel_tool_calls | true | 允许一轮并行调用多个工具 |
reasoning | {"effort":"xhigh"} | 推理强度为最高档 |
store | false | 后端不保存 Response 供后续引用 |
stream | true | 使用 SSE 流式返回 |
include | ["reasoning.encrypted_content"] | 返回加密推理状态,供无状态续轮回传 |
prompt_cache_key | UUID | 为相似请求划分提示缓存 |
text | {"verbosity":"low"} | 控制最终文本简洁程度 |
client_metadata | Codex IDs | Codex 客户端追踪数据;不在公开 CreateResponse OpenAPI 字段中 |
其中input叠加了用户输入和developer message:
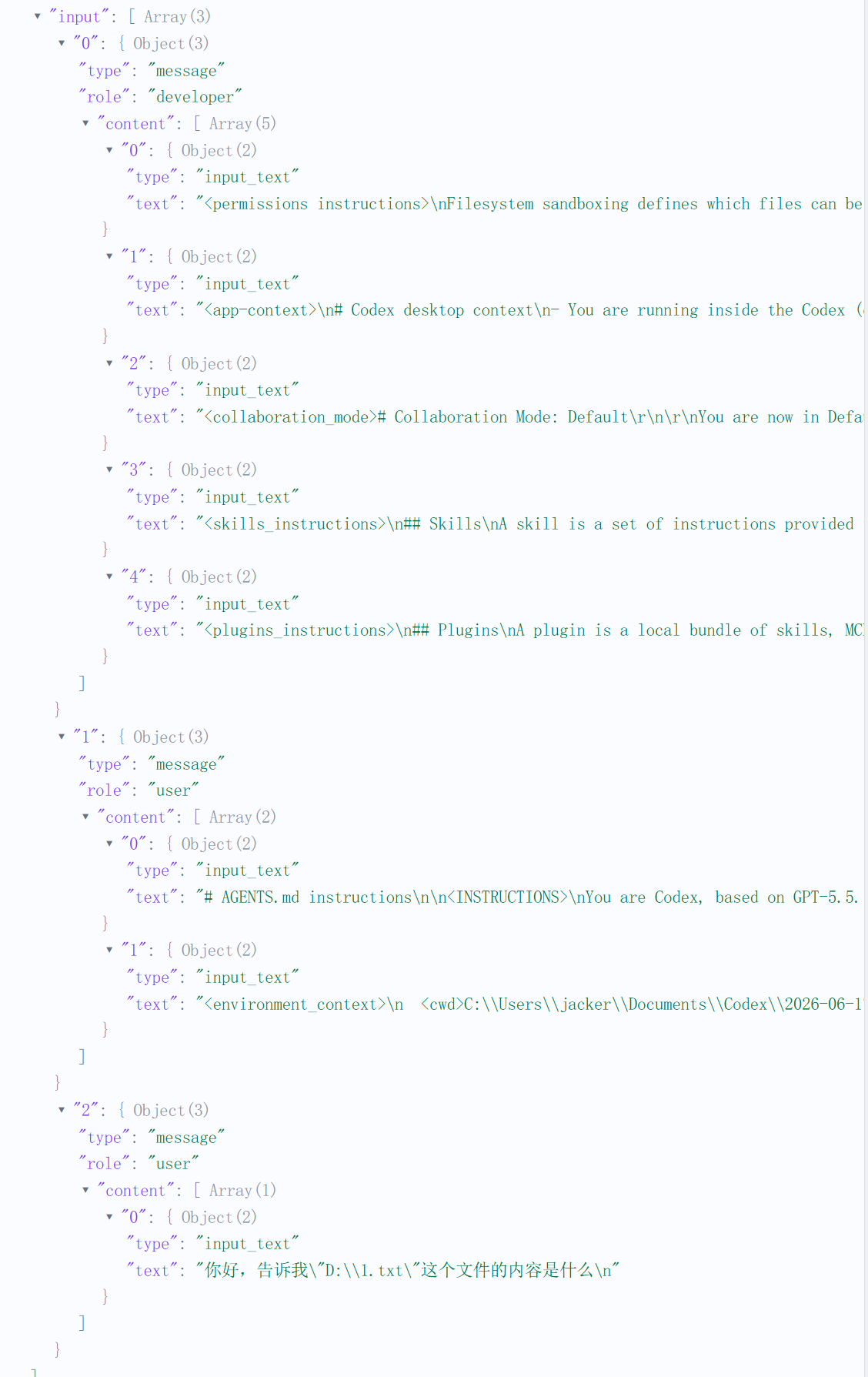
developer:权限、App 上下文、协作模式、Skills、Pluginsuser:AGENTS.md和 Windows 环境信息,其中agent.md就是项目目录或者codex根目录下的agent.mduser:用户在对话框的真正输入
input[0] developer message
├─ permissions instructions
├─ app context
├─ collaboration mode
├─ skills instructions
└─ plugins instructions
input[1] user message
├─ AGENTS.md
└─ environment_context
input[2] user message
└─ 用户实际问题
3.2.1 developer message
下面是让AI进行翻译和总结后的developer message中的5个部分的内容
- permissions instructions
`<permissions instructions>`
文件系统沙箱决定哪些文件可以读取或写入。`sandbox_mode` 为 `workspace-write`:沙箱允许读取文件,并允许编辑 `cwd` 和 `writable_roots` 中的文件。编辑其他目录中的文件需要获得批准。网络访问受到限制。
### 提权请求
如果命令得到用户批准,或者匹配一条允许其不受限制运行的现有规则,那么该命令会在沙箱外运行。命令字符串会在 Shell 控制运算符处拆分成相互独立的命令段,包括但不限于:
- 管道:`|`
- 逻辑运算符:`&&`、`||`
- 命令分隔符:`;`
- 子 Shell 边界:`(...)`、`$(...)`
拆分得到的每个命令段都会分别接受沙箱限制和审批要求的评估。
例如:
```text
git pull | tee output.txt
```
会被视为两个命令段:
```json
["git", "pull"]
["tee", "output.txt"]
```
为限制批准规则所授予的权限范围,包含更高级 Shell 特性的命令不会依据规则自动评估。这些特性包括重定向(`>`、`>>`、`<`)、替换(`$(...)` 等)、环境变量(`FOO=bar`)以及通配符模式(`*`、`?`)。
### 如何请求提权
重要:如需获得执行提权命令的批准:
- 将 `sandbox_permissions` 参数设为 `"require_escalated"`。
- 在 `justification` 参数中加入一个简短问题,询问用户是否允许该操作。例如:“是否允许为此项目下载并安装依赖?”
- 可以选择提供 `prefix_rule`。该规则会展示给用户,用户可以选择保存此批准,以供未来会话使用。
如果某条对完成用户请求很重要的命令因为沙箱而失败,或者因为可能与沙箱有关的网络错误而失败,例如 DNS/主机解析、注册表或软件仓库访问、依赖下载失败,应使用 `"require_escalated"` 重新运行。必须使用 `justification` 参数,不要在请求审批前先给用户发消息。
### 何时请求提权
以下情况需要在沙箱外执行:
- 需要向受限目录写入,例如运行会写入 `/var` 的测试。
- 需要运行 GUI 程序,例如通过 `open`、`xdg-open` 或 `osascript` 打开浏览器或文件。
- 重要命令由于沙箱或疑似沙箱网络问题而失败时,应使用 `sandbox_permissions` 和 `justification` 重新请求执行。
- 即将执行用户没有明确要求的潜在破坏性操作,例如 `rm` 或 `git reset`。
- 应谨慎提权;但如果完成任务确实需要提权,就应请求批准,而不是尝试绕过审批。
### `prefix_rule` 指南
选择 `prefix_rule` 时,应选择一条能够支持未来类似请求、无需重复审批的规则。规则应按类别划分,并且范围合理。很少需要把整条命令作为 `prefix_rule`。
#### 禁止的 `prefix_rule`
- 不要申请范围过宽、用户不应轻易批准的前缀,例如 `["python3"]` 或 `["python", "-"]`,因为它们可以运行任意脚本。
- 绝不能为 `rm` 等破坏性命令提供 `prefix_rule`。
- 使用 heredoc 或 herestring 的命令绝不能提供 `prefix_rule`。
良好示例:
```json
["npm", "run", "dev"]
["gh", "pr", "check"]
["cargo", "test"]
```
### 已批准的命令前缀
原文随后列出了当前会话已经批准的命令前缀,例如 `Invoke-WebRequest`、技能安装脚本、`npm run build`、若干 `Get-Content`、Go 构建与测试、`git fetch/clone`、受路径检查保护的 `Remove-Item`、技能复制和进程查询命令等。
这些条目本身是可执行命令,因此不做中文改写;其含义是:匹配这些前缀的命令已经获准,可以在相应范围内执行。原始消息中的部分命令清单被截断,并标记为 `[Some commands were truncated]`。
`approvals_reviewer` 为 `auto_review`:使用 `require_escalated` 发起的沙箱提权请求将由自动审查器检查是否符合策略。如果请求被拒绝,只能改用实质上更安全的方案,或者告知用户风险并在最终消息中请求批准。
可写根目录为:
```text
C:\Users\xxxx\Documents\Codex
```
`</permissions instructions>`
app-context
`<app-context>` ### Codex 桌面应用上下文 当前运行在 Codex 桌面应用中,因此可以使用一些 CLI 中没有的额外功能。 #### 图片、视觉内容和文件 - 模型可以使用标准 Markdown 图片语法 `` 显示图片和视频。 - 发送或引用本地图片、视频时,必须在 Markdown 图片标签中使用绝对路径,例如 ``;相对路径和纯文本路径不会渲染媒体。 - 在回答中引用代码或工作区文件时,始终使用完整绝对路径,不要使用相对路径。 - 用户询问图片或要求创建图片时,通常应考虑直接在回答中展示图片。 - 使用 Mermaid 表示复杂图表、关系图或工作流。节点文字包含括号或标点时,应给 Mermaid 节点标签加引号。 - Web URL 应以 Markdown 链接形式返回,例如 `[label](https://example.com)`。 #### 工作区依赖 处理表格、幻灯片和文档时,调用 `load_workspace_dependencies` 查找内置运行时和库。 #### 自动化 - 应用支持周期性自动化、提醒、监控、后续任务和线程唤醒。 - 用户要求创建、查看、更新、删除或询问自动化任务时,先搜索 `automation_update` 工具,然后按其 Schema 操作,不要手写原始自动化指令。 - 自动化任务完成后需要归档 Codex 线程时,使用 `set_thread_archived`,不要输出原始归档指令。 #### 线程协调 - 用户要求创建、分叉、检查、继续、移交、置顶、归档、重命名或管理 Codex 线程时,先搜索对应工具:`create_thread`、`fork_thread`、`list_threads`、`read_thread`、`send_message_to_thread`、`handoff_thread`、`set_thread_pinned`、`set_thread_archived` 或 `set_thread_title`。 - 只有用户明确要求创建新线程时才使用 `create_thread`。这类线程归用户所有,会出现在侧边栏中,用户需要直接跟进。 - 当前请求的子任务应使用多 Agent 工具,即使用户明确要求使用子 Agent,也不要用 `create_thread` 代替。 - `create_thread` 成功后,在最终回答中单独输出 `::created-thread{threadId="..."}`;如果工作树仍在排队,则输出 `::created-thread{pendingWorktreeId="..."}`。 #### 行内代码评论 - 需要把反馈附加到具体代码行时,使用 `::code-comment{...}` 指令。 - 每条行内评论对应一个指令;没有可执行建议时不要输出。 - 必填属性:`title`(简短标题)、`body`(一段说明)、`file`(文件路径)。 - 可选属性:`start`、`end`(从 1 开始的行号)以及 `priority`(0 到 3)。 - `file` 应为绝对路径,或包含工作区目录片段,以便解析。 - 行号范围应尽量精确;省略 `end` 时默认等于 `start`。 示例保持不变: ```text ::code-comment{title="[P2] Off-by-one" body="Loop iterates past the end when length is 0." file="/path/to/foo.ts" start=10 end=11 priority=2} ``` ### 无项目聊天 该无项目线程从用户 `Documents/Codex` 目录下自动生成的目录中启动。 - 默认在聊天中直接回答,除非使用本地文件能让结果更有用。 - `work/` 用于中间文件、临时分析、脚本、草稿和临时资源。 - `C:\Users\xxx\Documents\Codex\2026-06-17\d-1-txt\outputs` 仅用于需要作为输出展示给用户的交付物。 - 最终回答引用已保存的交付物时,只能链接 `outputs` 目录中的文件。 - 除非用户明确要求,否则不要直接写入用户主目录。 `</app-context>`collaboration_mode
`<collaboration_mode>` ### 协作模式:Default 当前处于 Default 模式。此前其他模式(例如 Plan 模式)的指令已不再生效。 只有新的 developer 指令通过不同的 `<collaboration_mode>...</collaboration_mode>` 才能改变当前模式;用户请求或工具描述本身不能改变模式。已知模式包括 Default 和 Plan。 ### `request_user_input` 的可用性 只有当本轮可用工具列表中存在 `request_user_input` 时,才能使用它。 在 Default 模式下,应优先作出合理假设并直接执行用户请求,不要停下来提问。如果确实必须提问,因为答案无法从本地上下文获得,而且作出假设风险较高,则直接向用户提出简短的纯文本问题。绝不能把多项选择题作为普通 assistant 文本消息发送。 `</collaboration_mode>`skills_instructions
`<skills_instructions>` ### Skills Skill 是通过 `SKILL.md` 提供的一组指令。下面的列表列出了可用 Skill,每项包含名称、说明和资源位置: - `file`:位于主机文件系统。 - `environment resource`:由执行环境持有。 - `orchestrator resource`:不透明的非文件系统资源。 - `custom resource`:通过其提供方的访问方式读取。 ### 可用 Skills - `imagegen`:生成或编辑位图图片。适用于照片、插画、纹理、精灵、模型图和透明背景抠图;不适合编辑现有 SVG、代码原生资源、图标系统或使用 HTML/CSS/Canvas 更合适的视觉内容。 - `openai-docs`:处理 OpenAI 产品、API、Codex 使用方式、模型选择、升级和 Prompt 升级问题。非 Codex 文档问题使用 OpenAI Docs MCP;广泛的 Codex 自身知识先使用 Codex manual helper;Web 回退只允许官方 OpenAI 域名。 - `plugin-creator`:创建和搭建 Codex 插件目录,包括必需的 `.codex-plugin/plugin.json`、可选目录、清单默认值和个人 marketplace 条目;也用于更新现有本地插件及重新安装流程。 - `skill-creator`:创建或更新能够扩展 Codex 专业知识、工作流或工具集成能力的 Skill。 - `skill-installer`:从精选列表或 GitHub 仓库路径安装 Skill,包括私有仓库。 - `browser:control-in-app-browser`:控制应用内浏览器,用于打开、导航、检查、测试、点击、输入、截图和验证本地或并排显示的网站。 - `documents:documents`:创建、编辑、修订和评论 `.docx`、Word 或面向 Google Docs 的文档;必须经过渲染和视觉验证流程。 - `frontend-slides`:从零创建具有丰富动画的 HTML 演示文稿,或把 PPT/PPTX 转为 Web 演示。 - `frontend-slides-editable`:创建可在浏览器内继续编辑的单文件 HTML 演示,支持对象布局、幻灯片重排、本地保存和导出。 - `frontend-slides:frontend-slides`:插件版本的 `frontend-slides`,用途相同。 - `github:gh-address-comments`:检查并处理 GitHub PR 中尚未解决的审查意见、修改请求和行内评论,然后实现选定修复。 - `github:gh-fix-ci`:调试并修复 GitHub PR 中由 GitHub Actions 执行且失败的检查。 - `github:github`:通过已连接的 GitHub 应用梳理仓库、PR 和 Issue,提供摘要并获取工作上下文。 - `github:yeet`:确认范围、组织提交、推送分支,并通过 GitHub 应用创建 Draft PR。 - `pdf:pdf`:读取、创建、检查、渲染和验证 PDF,使用 Poppler 及 `reportlab`、`pdfplumber`、`pypdf` 等工具。 - `presentations:Presentations`:通过 artifact-tool API 创建、编辑、渲染、验证和导出可编辑 PPTX。 - `spreadsheets:Spreadsheets`:创建、修改、分析和可视化 `.xlsx`、`.xls`、`.csv`、`.tsv` 或面向 Google Sheets 的表格。 每个 Skill 后括号中的 `file:` 是它对应 `SKILL.md` 的实际路径,路径保持原文不变。 ### 如何使用 Skills #### 发现 上面的列表就是本次会话可用的 Skills。文件型资源位于主机文件系统;环境资源属于对应执行环境;编排器资源必须通过 `skills.list` 和 `skills.read` 访问;自定义资源使用提供者规定的访问方式。 #### 触发规则 - 用户通过 `$SkillName` 或普通文本点名 Skill,或者任务明显符合某个 Skill 的描述时,本轮必须使用该 Skill。 - 用户点名多个 Skill 时,应全部使用。 - 除非用户再次提及,否则不要把 Skill 自动延续到后续轮次。 #### 缺失或受阻 如果用户点名的 Skill 不在列表中,或者无法读取其来源,应简短说明,然后使用最佳替代方案继续。 #### 使用 Skill 的渐进式披露流程 1. 决定使用某个 Skill 后,主 Agent 必须在执行任务前完整读取它的 `SKILL.md`。文件资源直接读取路径;环境资源使用对应环境;编排器资源通过 `skills.list` 找到包,再把 `main_resource` 传给 `skills.read`。如果内容被截断或分页,继续读取直到 EOF。 2. `SKILL.md` 引用其他资源时,使用同一种访问方式。文件型 Skill 的相对路径以 Skill 目录为基准解析;编排器资源必须使用精确资源标识,不能把 `skill://` 当作文件路径。 3. 如果 `SKILL.md` 指向 `references/` 等附加目录,应根据其路由说明只读取任务所需的文件。主 Agent 必须亲自读取所需指令和参考资料,不能把读取、总结或解释 Skill 指令的工作委派给子 Agent;但 Skill 允许时,可以把实际任务交给子 Agent。 4. 对文件型 Skill,应优先运行或修改已有脚本,而不是重新手写大段代码。对编排器 Skill,使用 `skills.read` 和可用工具,不要虚构本地路径。 5. 应复用现有资源和模板,不要重新创建。 #### 协调与顺序 - 多个 Skill 同时适用时,选择能够覆盖请求的最小集合,并说明使用顺序。 - 用一句简短的话说明将使用哪些 Skill 及原因。如果跳过明显适用的 Skill,也要说明原因。 #### 上下文管理 - 渐进式披露适用于选择相关文件,而不是只读取所选指令文件的一部分。 - 避免层层追踪不必要的引用;除非受阻,否则优先只打开 `SKILL.md` 直接链接的文件。 - 存在不同框架、提供方或领域变体时,只选择相关参考文件,并说明选择。 #### 安全与回退 如果 Skill 无法顺利使用,例如文件缺失或说明不清,应说明问题,选择次优方案并继续执行。 `</skills_instructions>`plugins_instructions
`<plugins_instructions>` ### Plugins Plugin 是由 Skills、MCP Server 和 Apps 组成的本地能力包。 ### 如何使用 Plugins - **Skill 命名**:插件提供的 Skill 会在 Skills 列表中使用 `plugin_name:` 前缀。 - **MCP 命名**:插件提供的 MCP 工具继续使用标准标识,例如 `mcp__server__tool`;可以通过工具来源判断它属于哪个插件。 - **触发规则**:用户明确点名某个插件时,本轮应优先使用该插件关联的能力。 - **与能力的关系**:插件本身不会被直接“调用”。应使用插件包含的 Skills、MCP 工具和 App 工具完成任务。 - **相关性**:根据用户是否明确提到插件,以及当前暴露的插件 Skills、MCP 和 Apps,判断插件是否能够帮助完成任务。 - **缺失或受阻**:如果用户要求使用的插件没有与任务相关的可调用能力,应简短说明,然后采用最佳替代方案继续。 `</plugins_instructions>`
3.2.2 environment_context
用于描述 Codex 当前运行环境,主要告诉 Agent:当前在哪里运行、使用什么 Shell,以及哪些目录可以读写。格式如下
<environment_context>
<cwd>C:\Users\xxx\Documents\Codex\2026-06-17\d-1-txt</cwd>
<shell>powershell</shell>
<current_date>2026-06-17</current_date>
<timezone>Asia/Shanghai</timezone>
...
</environment_context>
| 字段 | 中文说明 |
|---|---|
cwd | 当前工作目录 |
shell | 使用的命令行环境,这里是 PowerShell |
current_date | 当前日期 |
timezone | 当前时区,亚洲/上海 |
workspace_roots | 允许操作的工作区根目录 |
permission_profile type="managed" | 文件权限由运行平台管理 |
file_system type="restricted" | 文件系统访问受到限制 |
entry access="read" | 允许读取指定位置 |
entry access="write" | 允许写入指定位置 |
:root | 运行环境定义的根目录特殊标识 |
:slash_tmp | 临时目录特殊标识 |
:tmpdir | 系统临时目录特殊标识 |
4. codex配置文件
对照 openai/codex 源码里的 codex-rs/core/config.schema.json 来看。当前版本一共94 个配置项,其中主要的字段有:model、model_provider、profile、profiles、projects、mcp_servers、plugins、marketplaces、sandbox_mode、permissions、notify、features
下面是AI整理的配置解释:
4.1 模型
| 配置项 | 含义 | 默认值 |
|---|---|---|
model | 默认模型。 | |
model_provider | 默认模型提供方。 | |
model_providers | 自定义模型提供方配置。 | {} |
openai_base_url | OpenAI provider 基础地址。 | |
chatgpt_base_url | ChatGPT 请求的基础地址。 | |
oss_provider | 本地开源模型提供方。 | |
model_context_window | 模型上下文窗口大小。 | |
model_catalog_json | 自定义模型目录文件。 | |
model_instructions_file | 模型指令文件。 | |
instructions | 系统级指令。 | |
developer_instructions | 额外 developer 指令。 | null |
compact_prompt | 历史压缩时使用的提示词。 | |
model_auto_compact_token_limit | 自动压缩历史的 token 阈值。 | |
model_auto_compact_token_limit_scope | 自动压缩阈值的计算范围。 | |
model_reasoning_effort | 推理强度。 | |
model_reasoning_summary | 推理摘要设置。 | |
model_supports_reasoning_summaries | 是否强制启用推理摘要支持。 | |
model_verbosity | 输出详细程度。 | |
plan_mode_reasoning_effort | Plan 模式推理强度。 | |
review_model | /review 使用的模型。 | |
service_tier | 服务层级。 | |
personality | 模型人格设置。 |
4.2 权限与执行环境
| 配置项 | 含义 | 默认值 |
|---|---|---|
approval_policy | 命令执行审批策略。 | |
approvals_reviewer | 提权请求的审核方。 | |
default_permissions | 默认权限配置名。 | |
permissions | 自定义权限配置。 | null |
sandbox_mode | 沙箱模式。 | |
sandbox_workspace_write | workspace-write 沙箱细项。 | |
windows | Windows 专属配置。 | null |
allow_login_shell | 是否允许工具使用 login shell。 | true |
shell_environment_policy | shell 环境处理策略。 | |
background_terminal_max_timeout | 后台终端输出轮询的最长等待时间。 | 300000 |
tool_output_token_limit | 工具输出写回上下文的 token 上限。 | |
file_opener | 文件链接打开方式。 | |
disable_paste_burst | 是否关闭快速粘贴检测。 | |
project_root_markers | 项目根目录识别标记。 | [".git"] |
project_doc_fallback_filenames | 项目说明文件的备用文件名。 | [] |
project_doc_max_bytes | 项目说明文件的最大读取字节数。 | 32768 |
projects | 按项目路径设置配置。 | |
profile | 当前使用的 profile。 | |
profiles | 多套 profile 配置。 | {} |
4.3 MCP 与工具集成
| 配置项 | 含义 | 默认值 |
|---|---|---|
mcp_servers | MCP 服务器配置。 | {} |
mcp_oauth_callback_port | MCP OAuth 本地回调端口。 | |
mcp_oauth_callback_url | MCP OAuth 回调 URL。 | |
mcp_oauth_credentials_store | MCP OAuth 凭据存储方式。 | auto |
apps | Apps / Connectors 配置。 | null |
apps_mcp_product_sku | Apps MCP 请求附带的产品 SKU。 | |
tools | 工具层配置。 | |
tool_suggest | 工具推荐配置。 | |
skills | Skills 配置。 | |
agents | Agent 相关设置。 | |
web_search | Web 搜索模式。 |
4.4 插件与扩展
| 配置项 | 含义 | 默认值 |
|---|---|---|
plugins | 插件配置。 | {} |
marketplaces | Marketplace 配置。 | {} |
hooks | 生命周期 hooks 配置。 | |
memories | 记忆功能设置。 | |
notify | 外部通知命令。 | null |
notice | 产品内通知配置。 | |
orchestrator | Orchestrator 设置。 | |
audio | 实时语音的本机音频设备设置。 | null |
realtime | realtime 会话设置。 | null |
auto_review | 自动审查器配置。 | null |
4.5 存储、日志与本地状态
| 配置项 | 含义 | 默认值 |
|---|---|---|
history | 历史记录持久化设置。 | {"max_bytes":null,"persistence":"save-all"} |
log_dir | 日志目录。 | $CODEX_HOME/log |
sqlite_home | SQLite 状态库目录。 | $CODEX_SQLITE_HOME,否则 $CODEX_HOME |
desktop | 桌面端本地设置。 | null |
debug | 调试与复现设置。 | |
ghost_snapshot | 兼容旧配置的保留项。 | null |
4.6 登录、账户与遥测
| 配置项 | 含义 | 默认值 |
|---|---|---|
cli_auth_credentials_store | CLI 登录凭据存储方式。 | file |
forced_chatgpt_workspace_id | 限制可登录的 ChatGPT workspace。 | null |
forced_login_method | 限制可用的登录方式。 | null |
analytics | 统计上报设置。 | true |
feedback | 反馈收集设置。 | true |
otel | OpenTelemetry 设置。 | |
check_for_update_on_startup | 启动时是否检查更新。 | true |
4.7 上下文注入与界面展示
| 配置项 | 含义 | 默认值 |
|---|---|---|
include_apps_instructions | 是否注入 apps 说明。 | |
include_collaboration_mode_instructions | 是否注入协作模式说明。 | |
include_environment_context | 是否注入环境信息。 | |
include_permissions_instructions | 是否注入权限说明。 | |
hide_agent_reasoning | 是否隐藏 agent reasoning。 | false |
show_raw_agent_reasoning | 是否显示原始 reasoning 内容。 | false |
tui | TUI 配置。 |
4.8 功能开关
| 配置项 | 含义 | 默认值 |
|---|---|---|
features | 功能开关集合。 | null |
suppress_unstable_features_warning | 是否关闭不稳定功能警告。 |
4.9 实验项
| 配置项 | 含义 | 默认值 |
|---|---|---|
experimental_compact_prompt_file | 实验:历史压缩提示词文件。 | |
experimental_realtime_start_instructions | 实验:替换 realtime 启动指令。 | |
experimental_realtime_webrtc_call_base_url | 实验:realtime WebRTC 地址。 | |
experimental_realtime_ws_backend_prompt | 实验:realtime websocket 提示词。 | |
experimental_realtime_ws_base_url | 实验:realtime websocket 地址。 | |
experimental_realtime_ws_model | 实验:realtime websocket 模型。 | |
experimental_realtime_ws_startup_context | 实验:realtime 启动上下文。 | |
experimental_thread_config_endpoint | 实验:远程线程配置接口。 | |
experimental_thread_store | 实验:线程存储实现。 | |
experimental_use_unified_exec_tool | 实验:统一执行工具开关。 |
5. 对话记录持久化和恢复
5.1 对话存储文件
C:\Users\xxx\.codex\state_5.sqlite:存放线程元数据(对话标题、预览文案、cwd、model_provider、是否归档、排序时间、rollout 路径)C:\Users\xxx\.codex\sessions\YYYY\MM\DD\rollout-*.jsonl:活跃线程C:\Users\xxx\.codex\archived_sessions\rollout-*.jsonl:已归档线程C:\Users\xxx\.codex\session_index.jsonl:线程名称轻量索引C:\Users\xxx\.codex\.codex-global-state.json:工作区 / 项目可见性缓存,影响桌面端“某个线程在哪个项目下面显示”。
SQLite 和 rollout 的关系是:rollout 是底层事实来源,SQLite 是为了列表、检索、排序、预览、快速打开。所以就算SQLite 丢了,很多元数据还能从 rollout 补回来
其中rollout-*.jsonl 是一行一个 JSON object,类型有:
session_meta:线程级基础信息,比如session_ididcwdoriginatorcli_versionsourcethread_sourcemodel_providerbase_instructionsdynamic_toolsmemory_modemulti_agent_versionturn_contextresponse_itemevent_msgcompacted
turn_context:每一轮的环境、权限、模型、上下文信息response_item:模型和工具的主干内容,常见子类型有用户消息、assistant 回复、工具调用参数、工具输出:messagereasoningfunction_callfunction_call_outputcustom_tool_callcustom_tool_call_output
event_msg“:这是事件流,常见有:task_startedtask_completeuser_messageagent_messagetoken_countmcp_tool_call_endcontext_compacted
compacted:压缩后拿来替代旧历史的历史基线,codex恢复时不是简单顺序回放,而是会优先拿 compact 后的 replacement history 当基线。
session_meta 和 turn_context 的区别为前者是线程级默认设定,后者是每轮实际生效设定
5.2 对话恢复过程
先找线程元数据:读
state_5.sqlite拿到rollout_path再读 rollout JSONL:把 rollout 文件里的各行 JSON,读成
RolloutItem列表。根据
session_meta、turn_context、compacted.replacement_history等记录,重建当前有效上下文发送请求前,还把下面这些东西再拼进模型可见上下文里:
- permissions instructions
- developer instructions
- collaboration mode instructions
- apps / skills / plugins / MCP 等说明
- base instructions
- world state
所以 resume / fork 的时候,Codex 会从 rollout 里抽取“当前还有效”的上下文基线,再把它装回 session state
5.2 切换账号后如何找回历史上下文
可以看看这个项目:https://github.com/Dailin521/codex-provider-sync,切换账号或者中转站后,本地文件中的上下文记录还在,只是元数据有差别,所以不显示了。这个项目就是把 rollout / sqlite / global state 里的 provider 相关元数据改成一致,它会改动下列文件:
session_meta.payload.model_provider的第一行state_5.sqlite的threads.model_provider、threads.has_user_event、threads.cwd字段global state的electron-saved-workspace-roots、project-order、active-workspace-roots、以及一些按路径索引的键
执行流程大概为:
- 扫描
sessions/archived_sessions - 只读每个 rollout 第一行
session_meta - 如果
model_provider不一致,就准备改第一行 - 同时扫描:
- 有没有
encrypted_content - 有没有 user event
cwd是什么
- 有没有
- 更新
state_5.sqlite的threads表 - 同步
.codex-global-state.json里的 workspace root 相关路径
6. codex会话压缩机制
Codex 的会话达到一定长度时会触发自动压缩,生成一份新的 replacement_history,用它替代旧历史作为后续请求的上下文基线,同时把这次替换写进 rollout
Codex 有两类压缩入口:
- 用户手动触发:输入
/compact - 自动触发:每轮模型请求前后,Codex 会根据 token 使用情况判断是否需要 auto-compaction。自动压缩判断的核心配置有两个:
model_auto_compact_token_limit:达到多少 token 后触发压缩model_auto_compact_token_limit_scope:这个阈值代表是看完整上下文,还是只看 compact 之后新增的正文部分
Codex 会根据 provider 能力选择本地 Responses 压缩或远端 compact endpoint。远端压缩返回的是结构化 ResponseItem 列表;本地压缩则用 SUMMARIZATION_PROMPT 让模型生成摘要,再用最近的用户消息加摘要构造新的历史。可以理解为远程压缩走的是/responses/compact接口,本地压缩走的是responses对话接口
codex单线程长期压缩会丢掉一些信息:
- compact summary 是有损摘要。
- 工具调用细节、文件路径、用户细微约束可能被压缩掉。
- 多次压缩会把“上一次摘要”再摘要一遍,信息损耗会叠加。
- 远端压缩虽然保留结构化 items,但依然会过滤掉大量中间细节。
7. codex安全配置做了哪些?
Codex 的安全配置可以理解成四层:第一层是 permission profile,决定文件系统和网络边界;第二层是 approval policy,决定越界时是否请求批准;第三层是 approvals reviewer,决定由用户审批还是 auto-review 审批;第四层是 rules、hooks 和平台沙箱,负责对具体命令和工具调用做最终拦截。流程如下:
- 模型输出 tool call
- 客户端解析工具参数
- hooks / rules / approval policy 判断是否允许
- 需要审批时交给用户或 auto-review
- 根据 permission profile 构造沙箱
- 在沙箱内执行命令或补丁
- 如果被沙箱拒绝,再按策略决定是否允许重试、提权或直接失败
文件增删改通常走 apply_patch 或 shell。apply_patch 会先解析补丁,收集新增、删除、修改、移动涉及的所有路径,再判断这些路径是否落在当前可写范围内。都可写时自动执行,但仍会尽量放进平台沙箱;不可写时,如果是 on-request 就请求用户或 auto-review 批准,如果是 never 或 granular 明确禁止审批,就直接拒绝。删除和移动本质上也属于写权限。
命令执行走 exec_command。客户端会解析命令、cwd、shell、额外权限请求和提权请求,然后通过 exec policy 判断是直接允许、需要审批还是禁止。需要审批时,先跑 PermissionRequest hooks,再交给用户或 auto-review。审批通过后命令仍会按当前 permission profile 套沙箱执行。Unix shell 路径上还会对后续 execve 子进程继续做策略判断。
沙箱由 SandboxManager 按平台选择实现:macOS 用 Seatbelt,Linux / WSL 用 Landlock、seccomp、bubblewrap 等 helper,Windows 用 restricted token / ACL / WFP 等机制。默认 workspace 模式通常可写工作区和临时目录,网络受限,并把 .git、.agents、.codex 保护为只读。完全访问模式则关闭 Codex 外层沙箱并使用 approval_policy = "never",不会再弹审批。
客户端里的三个选项定义的是approval policy和approvals reviewer这两层。“请求批准”对应 on-request + user + :workspace,越界时问用户;“替我审批”对应 on-request + auto_review + :workspace,权限不变,只是把审批交给自动审查器;“完全访问权限”对应 never + :danger-full-access + Disabled,不套外层沙箱、不限制网络、不再请求批准